ConDA: Unsupervised Domain Adaptation for LiDAR Segmentation via Regularized Domain Concatenation
- 1National University of Singapore
- 2Motional
- *Work done as an autonomous vehicle intern at Motional
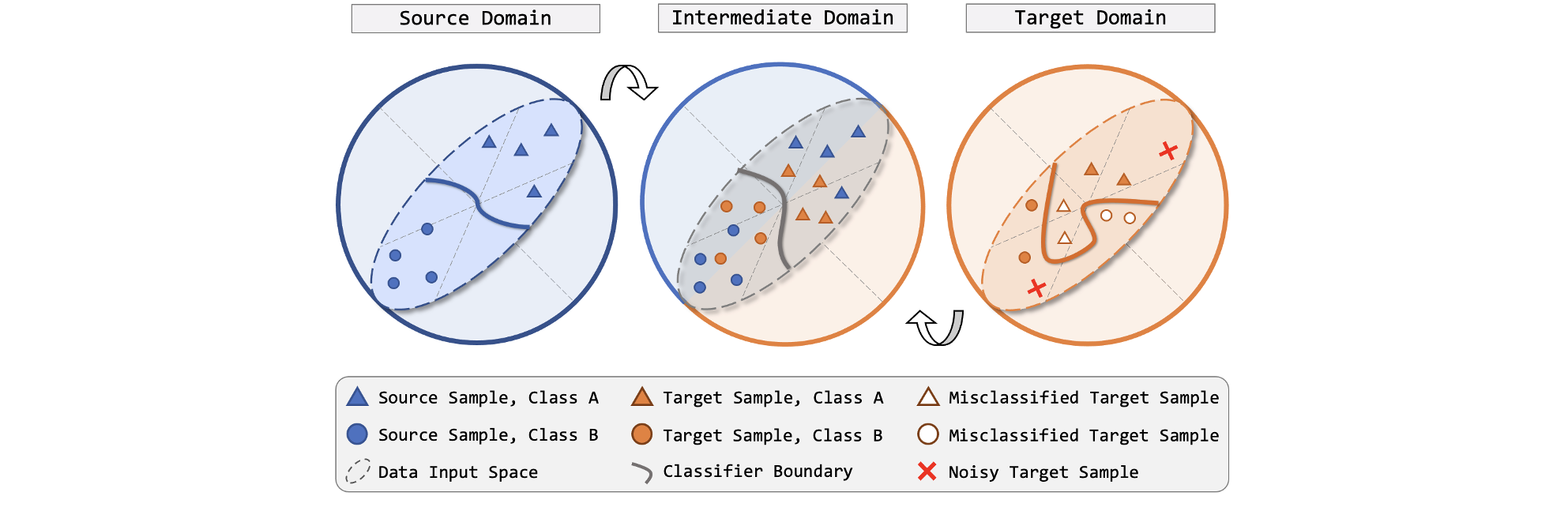
Figure 1. Conceptual illustration of regularized domain concatenation. Proper classifier boundary can be delineated under supervised learning fashion for the labeled source domain (left). The unlabeled target domain (right) suffers from discrepancies, often resulting in massive false predictions if the source model is directly used on target. We propose to explicitly bridge the source and target by an intermediate domain (middle), where fine-grained interchanges from both domains are introduced. This is achieved by concatenating the range-view projection stripes of the source and target LiDAR point clouds and regularizing the target entropy.
Abstract
Transferring knowledge learned from the labeled source domain to the raw target domain for unsupervised domain adaptation (UDA) is essential to the scalable deployment of autonomous driving systems.
State-of-the-art methods in UDA often employ a key idea: utilizing joint supervision signals from both source and target domains for self-training.
In this work, we improve and extend this aspect. We present ConDA, a concatenation-based domain adaptation framework for LiDAR segmentation that: 1) constructs an intermediate domain consisting of fine-grained interchange signals from both source and target domains without destabilizing the semantic coherency of objects and background around the ego-vehicle;
and 2) utilizes the intermediate domain for self-training.
To improve the network training on the source domain and self-training on the intermediate domain, we propose an anti-aliasing regularizer and an entropy aggregator to reduce the negative effect caused by the aliasing artifacts and noisy pseudo labels.
Through extensive studies, we demonstrate that ConDA significantly outperforms prior arts in mitigating domain gaps.
Resources




Cross-City UDA Benchmark

HighLights
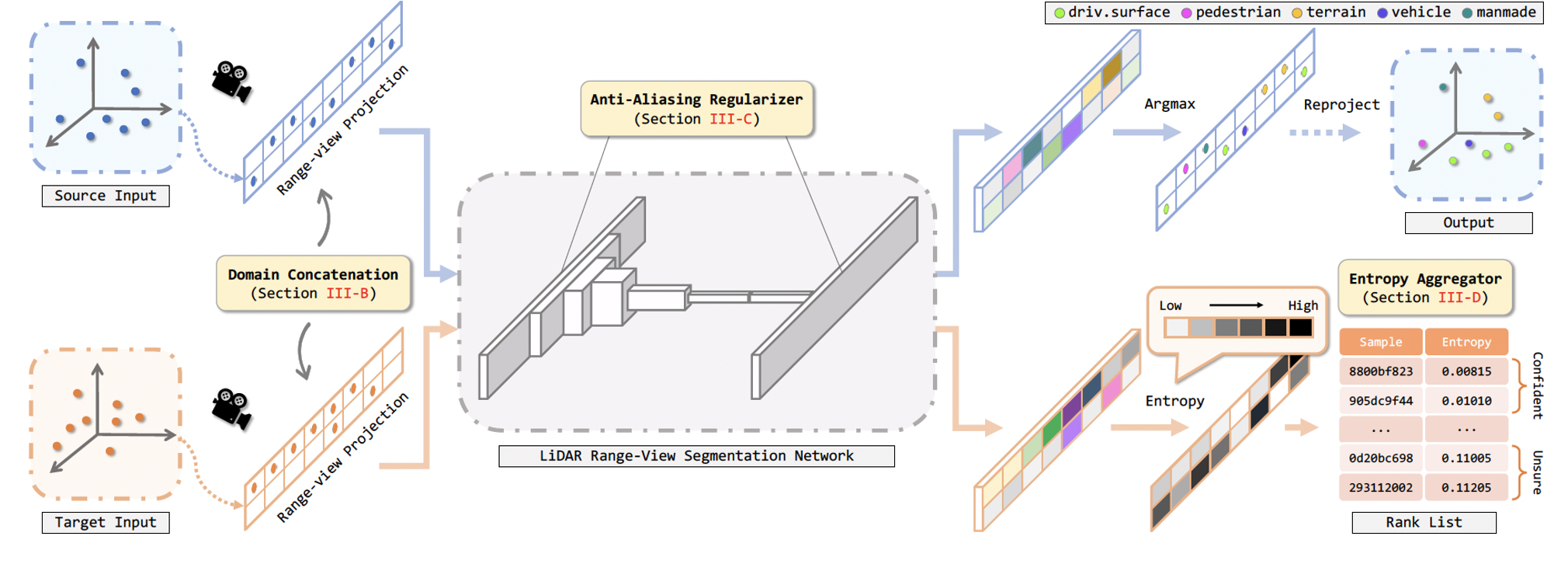 Figure 2. Overview of our concatenation-based domain adaptation (ConDA) framework. After preprocessing, sample stripes from both domains
are mixed via RV concatenation. The concatenated inputs are fed into the segmentation network for feature extraction. We include anti-aliasing
regularizers inside convolution operations to suppress the learning of high-frequency aliasing artifacts. The segmented RV cells are then projected
back to the point clouds. Here the target prediction part is omitted for simplicity. To mitigate the impediment caused by erroneous target predictions, we
design an entropy aggregator which splits samples into a confident set and an unsure set and disables the usage of samples from the latter set.
Figure 2. Overview of our concatenation-based domain adaptation (ConDA) framework. After preprocessing, sample stripes from both domains
are mixed via RV concatenation. The concatenated inputs are fed into the segmentation network for feature extraction. We include anti-aliasing
regularizers inside convolution operations to suppress the learning of high-frequency aliasing artifacts. The segmented RV cells are then projected
back to the point clouds. Here the target prediction part is omitted for simplicity. To mitigate the impediment caused by erroneous target predictions, we
design an entropy aggregator which splits samples into a confident set and an unsure set and disables the usage of samples from the latter set.
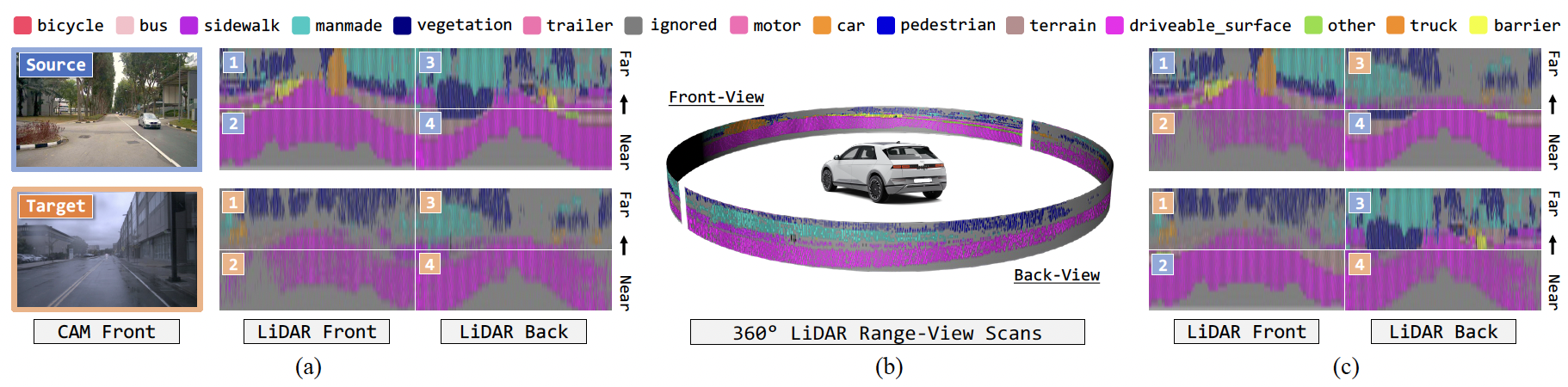 Figure 3. Illustrative examples for domain concatenation. (a) Visual RGB and LiDAR range-view (RV) projections of the source (ground-truth) and target
(pseudo-labels) domains. Images adopted from nuScenes. (b) Cylindrical representation of LiDAR RV. (c) Concatenated examples. Mixing domains
using our ConDA strategy yields semantically realistic intermediate domain samples for self-training.
Figure 3. Illustrative examples for domain concatenation. (a) Visual RGB and LiDAR range-view (RV) projections of the source (ground-truth) and target
(pseudo-labels) domains. Images adopted from nuScenes. (b) Cylindrical representation of LiDAR RV. (c) Concatenated examples. Mixing domains
using our ConDA strategy yields semantically realistic intermediate domain samples for self-training.
 Figure 4. Qualitative results from both the bird’s eye view and rangeview. To highlight the difference between the predictions and ground-truth, the correct
and incorrect points/pixels are painted in green and red, respectively.
Figure 4. Qualitative results from both the bird’s eye view and rangeview. To highlight the difference between the predictions and ground-truth, the correct
and incorrect points/pixels are painted in green and red, respectively.
Bibtex
@article{kong2021conda,
title={ConDA: Unsupervised domain adaptation for LiDAR segmentation via regularized domain concatenation},
author={Lingdong Kong and Niamul Quader and Venice Erin Liong},
journal={arXiv preprint arXiv:2111.15242},
year={2021}
}