LaserMix for Semi-Supervised LiDAR
Semantic Segmentation
- S-Lab, Nanyang Technological University
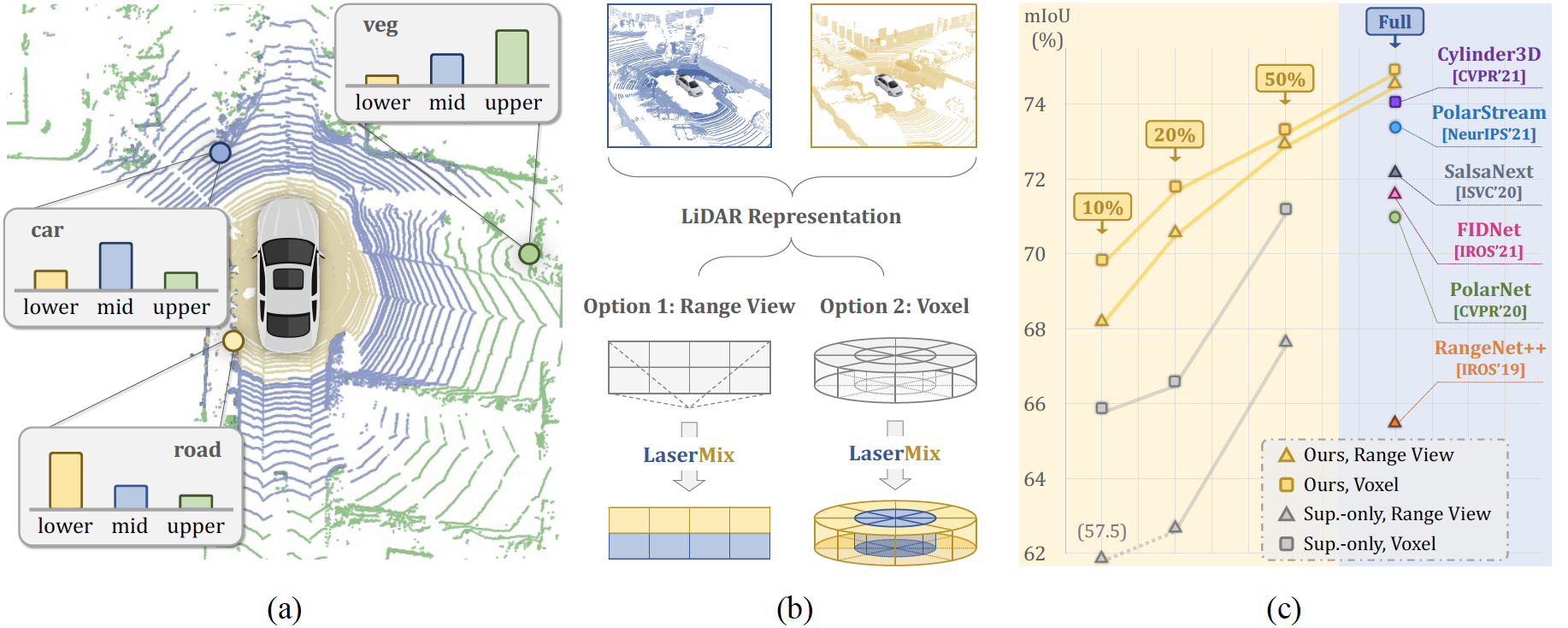
Figure 1. An Overview of LaserMix. (a) LiDAR scans contain strong spatial prior. Objects and backgrounds around the ego-vehicle have a patterned distribution on different (e.g., lower, middle, upper) laser beams. (b) Following the scene structure, the proposed LaserMix blends beams from different LiDAR scans, which is compatible with various popular LiDAR representations, such as the range view and voxel representations. (c) LaserMix achieves superior results over SoTA methods in both low-data (10%, 20%, and 50% labels) and high-data (full labels) regimes on nuScenes.
Abstract
Densely annotating LiDAR point clouds is costly, which restrains the scalability
of fully-supervised learning methods. In this work, we study the underexplored
semi-supervised learning (SSL) in LiDAR segmentation. Our core idea is to leverage
the strong spatial cues of LiDAR point clouds to better exploit unlabeled data.
We propose LaserMix to mix laser beams from different LiDAR scans, and then
encourage the model to make consistent and confident predictions before and after
mixing. Our framework has three appealing properties: 1) Generic: LaserMix
is agnostic to LiDAR representations (e.g., range view and voxel), and hence our
SSL framework can be universally applied. 2) Statistically grounded: We provide
a detailed analysis to theoretically explain the applicability of the proposed
framework. 3) Effective: Comprehensive experimental analysis on popular LiDAR
segmentation datasets (nuScenes, SemanticKITTI, and ScribbleKITTI) demonstrates
our effectiveness and superiority. Notably, we achieve competitive results
over fully-supervised counterparts with 2x to 5x fewer labels and improve the
supervised-only baseline significantly by 10.8% on average. We hope this concise
yet high-performing framework could facilitate future research in semi-supervised
LiDAR segmentation.
Resources




HighLights
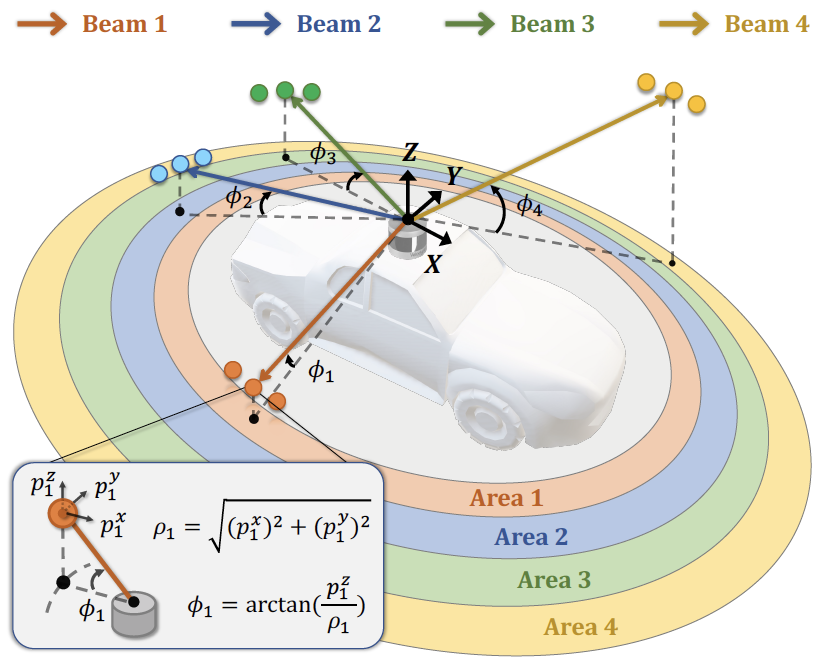 Figure 2. Laser partition example. We group
points whose inclinations ϕ are within the
same inclination range into the same area.
Figure 2. Laser partition example. We group
points whose inclinations ϕ are within the
same inclination range into the same area.
Leveraging the Spatial Prior for SSL
The distribution of real-world objects/backgrounds has a strong correlation to their spatial positions in LiDAR scans, as shown in Fig. 1 (a). Objects and backgrounds inside a specified spatial area of a LiDAR point cloud follow similar patterns, e.g., the close-range area is most likely road while the long-range area consists of building, vegetation, etc. In another word, there exists a spatial area a ∈ A where LiDAR points and semantic labels inside the area (denoted as Xin and Yin, respectively) will have relatively low variations. Formally, the conditional entropy H(Xin, Yin|A) is smaller. In this work, we propose to encourage the segmentation model to make confident and consistent predictions at a predefined area, regardless of the data outside the area. The predefined area set A determines the “strength” of the prior.
The distribution of real-world objects/backgrounds has a strong correlation to their spatial positions in LiDAR scans, as shown in Fig. 1 (a). Objects and backgrounds inside a specified spatial area of a LiDAR point cloud follow similar patterns, e.g., the close-range area is most likely road while the long-range area consists of building, vegetation, etc. In another word, there exists a spatial area a ∈ A where LiDAR points and semantic labels inside the area (denoted as Xin and Yin, respectively) will have relatively low variations. Formally, the conditional entropy H(Xin, Yin|A) is smaller. In this work, we propose to encourage the segmentation model to make confident and consistent predictions at a predefined area, regardless of the data outside the area. The predefined area set A determines the “strength” of the prior.
 Figure 3. Illustration for LiDAR point partition.
Figure 3. Illustration for LiDAR point partition.
Laser Beam Partition & Mixing
LiDAR sensors have a fixed number of laser beams which are emitted isotropically around the ego-vehicle with predefined inclination angles. To obtain a proper set of spatial areas A, we propose to partition the LiDAR point cloud based on laser beams. We mix the aforementioned laser partitioned areas A from two scans in an intertwining way, i.e., one takes from odd-indexed areas A1 = {a1, a3, ...} and the other takes from even-indexed areas A2 = {a2, a4, ...}, so that each area’s neighbor will be from the other scan. We find that the laser partition & mixing effectively “excites” a strong spatial prior in the LiDAR data; it significantly outperforms other partition choices, including: random points (MixUp-like partition), random areas (CutMix-like partition), and other heuristics like azimuth α (sensor horizontal direction) or radius r (sensor range directon) partitions.
LiDAR sensors have a fixed number of laser beams which are emitted isotropically around the ego-vehicle with predefined inclination angles. To obtain a proper set of spatial areas A, we propose to partition the LiDAR point cloud based on laser beams. We mix the aforementioned laser partitioned areas A from two scans in an intertwining way, i.e., one takes from odd-indexed areas A1 = {a1, a3, ...} and the other takes from even-indexed areas A2 = {a2, a4, ...}, so that each area’s neighbor will be from the other scan. We find that the laser partition & mixing effectively “excites” a strong spatial prior in the LiDAR data; it significantly outperforms other partition choices, including: random points (MixUp-like partition), random areas (CutMix-like partition), and other heuristics like azimuth α (sensor horizontal direction) or radius r (sensor range directon) partitions.
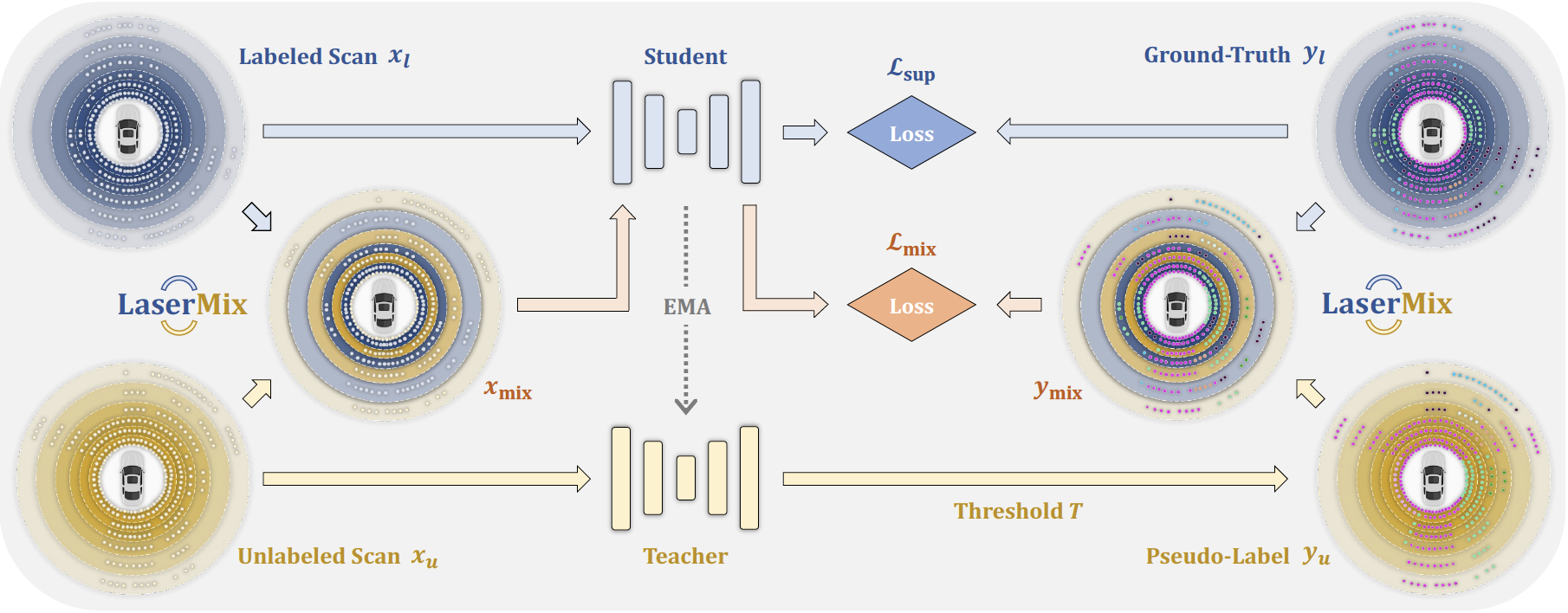 Figure 4. Framework overview. Labeled scan is fed into the Student net to compute the supervised
loss (w/ ground-truth). Unlabeled scan and the generated pseudo-label are mixed with
the labeled scan and its labels via LaserMix to produce mixed data, which is then fed into the Student
net to compute the mix loss. Additionally, we adopt the EMA update for the Teacher net
and compute the mean teacher loss over Student net’s and Teacher net’s predictions.
Figure 4. Framework overview. Labeled scan is fed into the Student net to compute the supervised
loss (w/ ground-truth). Unlabeled scan and the generated pseudo-label are mixed with
the labeled scan and its labels via LaserMix to produce mixed data, which is then fed into the Student
net to compute the mix loss. Additionally, we adopt the EMA update for the Teacher net
and compute the mean teacher loss over Student net’s and Teacher net’s predictions.
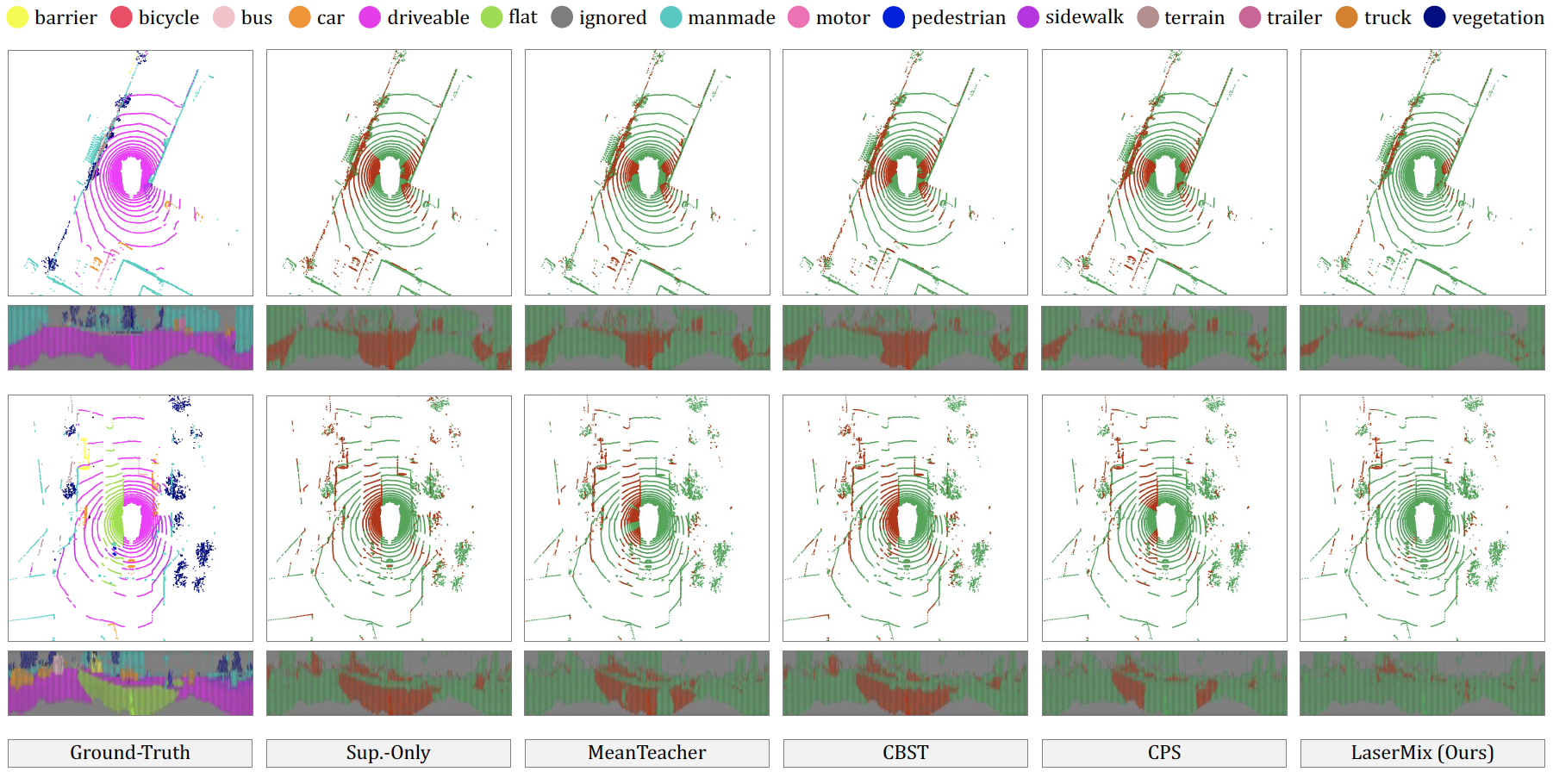 Figure 5. Qualitative results from LiDAR top view and range view. The correct and incorrect
predictions are painted in green and red to highlight the difference. Best viewed in color.
Figure 5. Qualitative results from LiDAR top view and range view. The correct and incorrect
predictions are painted in green and red to highlight the difference. Best viewed in color.
Bibtex
@article{kong2022lasermix,
title={LaserMix for Semi-Supervised LiDAR Semantic Segmentation},
author={Kong, Lingdong and Ren, Jiawei and Pan, Liang and Liu, Ziwei},
journal={arXiv preprint arXiv:2207.00026},
year={2022}
}