LiMoE: Mixture of LiDAR Representation Learners from Automotive Scenes
- Xiang Xu*,1
- Lingdong Kong*,2,3
- Hui Shuai4
- Liang Pan3
- Ziwei Liu5
- Qingshan Liu4
- 1Nanjing University of Aeronautics and Astronautics
- 2National University of Singapore
- 3Shanghai AI Laboratory
- 4Nanjing University of Posts and Telecommunications
- 5S-Lab, Nanyang Technological University
Abstract
LiDAR data pretraining offers a promising approach to leveraging large-scale, readily available datasets for enhanced data utilization. However, existing methods predominantly focus on sparse voxel representation, overlooking the complementary attributes provided by other LiDAR representations.
In this work, we propose LiMoE, a framework that integrates the Mixture of Experts (MoE) paradigm into LiDAR data representation learning to synergistically combine multiple representations, such as range images, sparse voxels, and raw points.
Our approach consists of three stages: (i) Image-to-LiDAR Pretraining, which transfers prior knowledge from images to point clouds across different representations; (ii) Contrastive Mixture Learning (CML), which uses MoE to adaptively activate relevant attributes from each representation and distills these mixed features into a unified 3D network; (iii) Semantic Mixture Supervision (SMS), which combines semantic logits from multiple representations to boost downstream segmentation performance.
Extensive experiments across 11 large-scale LiDAR datasets demonstrate our effectiveness and superiority. The code and model checkpoints have been made publicly accessible.
Resource



HighLight
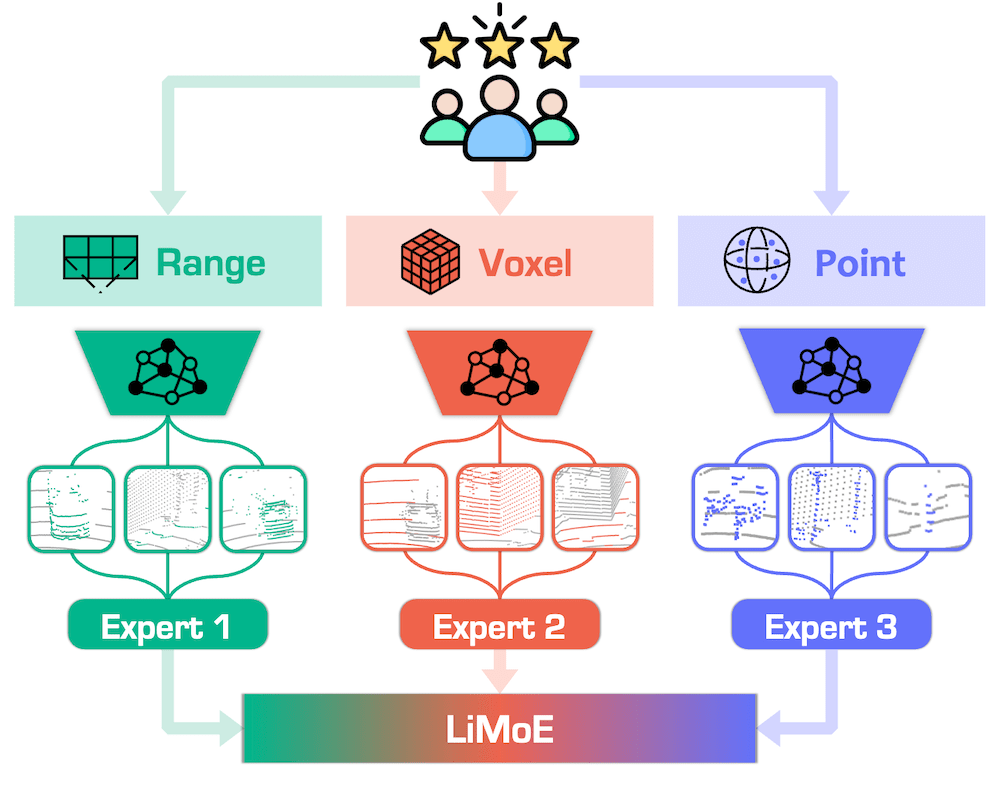 Figure 1. Illustration of the proposed mixture of LiDAR representation learning (LiMoE) design.
We observe unique patterns of each LiDAR representation (range, voxel, and point) in image-to-LiDAR data pretraining. Our framework aims to integrate distinct attributes from different LiDAR representations into a unified feature space, enabling enhanced 3D scene understanding.
Figure 1. Illustration of the proposed mixture of LiDAR representation learning (LiMoE) design.
We observe unique patterns of each LiDAR representation (range, voxel, and point) in image-to-LiDAR data pretraining. Our framework aims to integrate distinct attributes from different LiDAR representations into a unified feature space, enabling enhanced 3D scene understanding.
Mixture of LiDAR Representation Learning
In this work, we present LiMoE, a novel framework that synergistically integrates three LiDAR representations into a unified representation for feature learning. The framework operates in three stages: (1) Image-to-LiDAR pretraining, where knowledge from pretrained image backbone is transferred to LiDAR points for each representation, initializing diverse representation-specific features; (2) Contrastive mixture learning (CML), which fuses pretrained features across representations into a unified representation, leveraging their complementary strengths; and (3) Semantic mixture supervision (SMS), which enhances downstream performance by combining multiple semantic logits.
We observe that pretrained models with different LiDAR representations capture distinct data attributes. Range images primarily focus on middle laser beams and distances, sparse voxels emphasize upper beams and longer distances, while points capture lower beams and near distances.
In this work, we present LiMoE, a novel framework that synergistically integrates three LiDAR representations into a unified representation for feature learning. The framework operates in three stages: (1) Image-to-LiDAR pretraining, where knowledge from pretrained image backbone is transferred to LiDAR points for each representation, initializing diverse representation-specific features; (2) Contrastive mixture learning (CML), which fuses pretrained features across representations into a unified representation, leveraging their complementary strengths; and (3) Semantic mixture supervision (SMS), which enhances downstream performance by combining multiple semantic logits.
We observe that pretrained models with different LiDAR representations capture distinct data attributes. Range images primarily focus on middle laser beams and distances, sparse voxels emphasize upper beams and longer distances, while points capture lower beams and near distances.
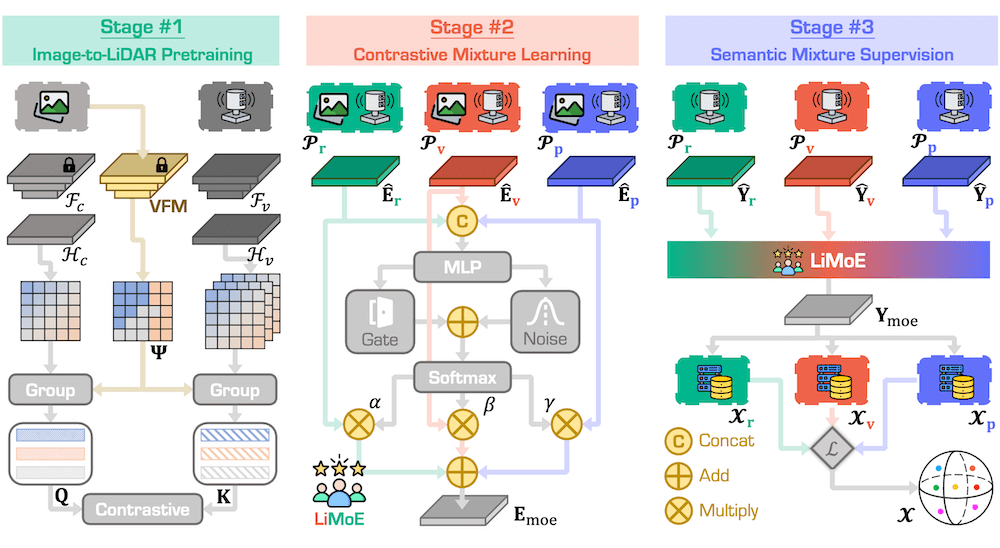 Figure 2. Overview of the LiMoE framework.
Our design consists of three stages: (1) The image-to-LiDAR pretraining transfers knowledge from images to various LiDAR representations;
(2) The contrastive mixture learning (CML) integrates the MoE framework to mix data attributes into a unified representation for pretraining;
and (3) The semantic mixture supervision (SMS) fuses semantic logits from multiple representations to further enhance performance across different downstream tasks.
Figure 2. Overview of the LiMoE framework.
Our design consists of three stages: (1) The image-to-LiDAR pretraining transfers knowledge from images to various LiDAR representations;
(2) The contrastive mixture learning (CML) integrates the MoE framework to mix data attributes into a unified representation for pretraining;
and (3) The semantic mixture supervision (SMS) fuses semantic logits from multiple representations to further enhance performance across different downstream tasks.
 Figure 3. Cosine similarity between learned features of a query point (denoted as the red dot) and:
(1) the features of the image of the same scene (the first row); and (2) the features of the LiDAR points projected onto the image (the second row). Best viewed in colors.
Figure 3. Cosine similarity between learned features of a query point (denoted as the red dot) and:
(1) the features of the image of the same scene (the first row); and (2) the features of the LiDAR points projected onto the image (the second row). Best viewed in colors.
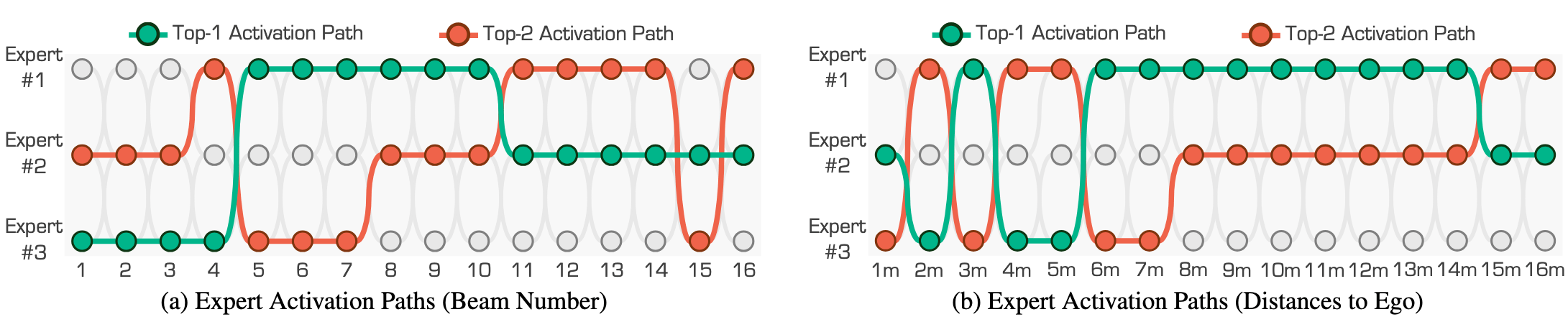 Figure 4. Visual interpretations of the expert activation paths in Contrastive Mixture Learning (CML).
The experts are #1 range view, #2 voxel, and #3 point, respectively.
Figure 4. Visual interpretations of the expert activation paths in Contrastive Mixture Learning (CML).
The experts are #1 range view, #2 voxel, and #3 point, respectively.
Table 1. Comparisons of state-of-the-art LiDAR pretraining methods pretrained on nuScenes and fine-tuned on nuScenes, SemanticKITTI, and Waymo Open datasets, respectively, with specified data portions. LP denotes linear probing with frozen backbones. All scores are given in percentage (%).
| Method | Venue | Backbone (2D) | Backbone (3D) | Expert | nuScenes | KITTI | Waymo | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LP | 1% | 5% | 10% | 25% | Full | 1% | 1% | |||||
| Random | - | - | - | - | 8.10 | 30.30 | 47.84 | 56.15 | 65.48 | 74.66 | 39.50 | 39.41 |
| PPKT | arXiv'21 | ResNet-50 | MinkUNet | Single | 35.90 | 37.80 | 53.74 | 60.25 | 67.14 | 74.52 | 44.00 | 47.60 |
| SLidR | CVPR'22 | ResNet-50 | MinkUNet | Single | 38.80 | 38.30 | 52.49 | 59.84 | 66.91 | 74.79 | 44.60 | 47.12 |
| ST-SLidR | CVPR'23 | ResNet-50 | MinkUNet | Single | 40.48 | 40.75 | 54.69 | 60.75 | 67.70 | 75.14 | 44.72 | 44.93 |
| TriCC | CVPR'23 | ResNet-50 | MinkUNet | Single | 38.00 | 41.20 | 54.10 | 60.40 | 67.60 | 75.60 | 45.90 | - |
| Seal | NeurIPS'23 | ResNet-50 | MinkUNet | Single | 44.95 | 45.84 | 55.64 | 62.97 | 68.41 | 75.60 | 46.63 | 49.34 |
| CSC | CVPR'24 | ResNet-50 | MinkUNet | Single | 46.00 | 47.00 | 57.00 | 63.30 | 68.60 | 75.70 | 47.20 | - |
| HVDistill | IJCV'24 | ResNet-50 | MinkUNet | Single | 39.50 | 42.70 | 56.60 | 62.90 | 69.30 | 76.60 | 49.70 | - |
| SLidR | CVPR'22 | ViT-S | MinkUNet | Single | 44.70 | 41.16 | 53.65 | 61.47 | 66.71 | 74.20 | 44.67 | 47.57 |
| +LiMoE | Ours | ViT-S | MinkUNet | Multi | 45.80 | 46.82 | 57.54 | 63.85 | 68.61 | 75.64 | 46.81 | 48.81 |
| Seal | NeurIPS'23 | ViT-S | MinkUNet | Single | 45.16 | 44.27 | 55.13 | 62.46 | 67.64 | 75.58 | 46.51 | 48.67 |
| SuperFlow | ECCV'24 | ViT-S | MinkUNet | Single | 46.44 | 47.81 | 59.44 | 64.47 | 69.20 | 76.54 | 47.97 | 49.94 |
| +LiMoE | Ours | ViT-S | MinkUNet | Multi | 48.20 | 49.60 | 60.54 | 65.65 | 71.39 | 77.27 | 49.53 | 51.42 |
| SLidR | CVPR'22 | ViT-B | MinkUNet | Single | 45.35 | 41.64 | 55.83 | 62.68 | 67.61 | 74.98 | 45.50 | 48.32 |
| +LiMoE | Ours | ViT-B | MinkUNet | Multi | 46.56 | 46.89 | 58.09 | 63.87 | 69.02 | 75.87 | 47.96 | 49.50 |
| Seal | NeurIPS'23 | ViT-B | MinkUNet | Single | 46.59 | 45.98 | 57.15 | 62.79 | 68.18 | 75.41 | 47.24 | 48.91 |
| SuperFlow | ECCV'24 | ViT-B | MinkUNet | Single | 47.66 | 48.09 | 59.66 | 64.52 | 69.79 | 76.57 | 48.40 | 50.20 |
| +LiMoE | Ours | ViT-B | MinkUNet | Multi | 49.07 | 50.23 | 61.51 | 66.17 | 71.56 | 77.81 | 50.30 | 51.77 |
| SLidR | CVPR'22 | ViT-L | MinkUNet | Single | 45.70 | 42.77 | 57.45 | 63.20 | 68.13 | 75.51 | 47.01 | 48.60 |
| +LiMoE | Ours | ViT-L | MinkUNet | Multi | 47.43 | 46.92 | 58.41 | 64.54 | 69.69 | 76.32 | 48.25 | 50.23 |
| Seal | NeurIPS'23 | ViT-L | MinkUNet | Single | 46.81 | 46.27 | 58.14 | 63.27 | 68.67 | 75.66 | 47.55 | 50.02 |
| SuperFlow | ECCV'24 | ViT-L | MinkUNet | Single | 48.01 | 49.95 | 60.72 | 65.09 | 70.01 | 77.19 | 49.07 | 50.67 |
| +LiMoE | Ours | ViT-L | MinkUNet | Multi | 49.35 | 51.41 | 62.07 | 66.64 | 71.59 | 77.85 | 50.69 | 51.93 |
Table 2. Domain generalization study of different LiDAR pretraining methods pretrained on the nuScenes dataset and fine-tuned on a collection of seven different LiDAR semantic segmentation datasets, respectively, with specific data portions. All scores are given in percentage (%).
| Method | Venue | ScribbleKITTI | RELLIS-3D | SemanticPOSS | SemanticSTF | SynLiDAR | DAPS-3D | Synth4D | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1% | 10% | 1% | 10% | Half | Full | Half | Full | 1% | 10% | Half | Full | 1% | 10% | ||
| Random | - | 23.81 | 47.60 | 38.46 | 53.60 | 46.26 | 54.12 | 48.03 | 48.15 | 19.89 | 44.74 | 74.32 | 79.38 | 20.22 | 66.87 |
| PPKT | arXiv'21 | 36.50 | 51.67 | 49.71 | 54.33 | 50.18 | 56.00 | 50.92 | 54.69 | 37.57 | 46.48 | 78.90 | 84.00 | 61.10 | 62.41 |
| SLidR | CVPR'22 | 39.60 | 50.45 | 49.75 | 54.57 | 51.56 | 55.36 | 52.01 | 54.35 | 42.05 | 47.84 | 81.00 | 85.40 | 63.10 | 62.67 |
| +LiMoE | Ours | 41.48 | 53.41 | 51.28 | 55.21 | 53.14 | 56.42 | 53.16 | 55.51 | 43.72 | 49.57 | 81.70 | 85.76 | 64.69 | 66.79 |
| Seal | NeurIPS'23 | 40.64 | 52.77 | 51.09 | 55.03 | 53.26 | 56.89 | 53.46 | 55.36 | 43.58 | 49.26 | 81.88 | 85.90 | 64.50 | 66.96 |
| SuperFlow | ECCV'24 | 42.70 | 54.00 | 52.83 | 55.71 | 54.41 | 57.33 | 54.72 | 56.57 | 44.85 | 51.38 | 82.43 | 86.21 | 65.31 | 69.43 |
| +LiMoE | Ours | 43.95 | 55.96 | 53.74 | 56.67 | 55.42 | 57.83 | 55.60 | 57.31 | 45.79 | 52.27 | 83.24 | 86.68 | 66.54 | 71.07 |
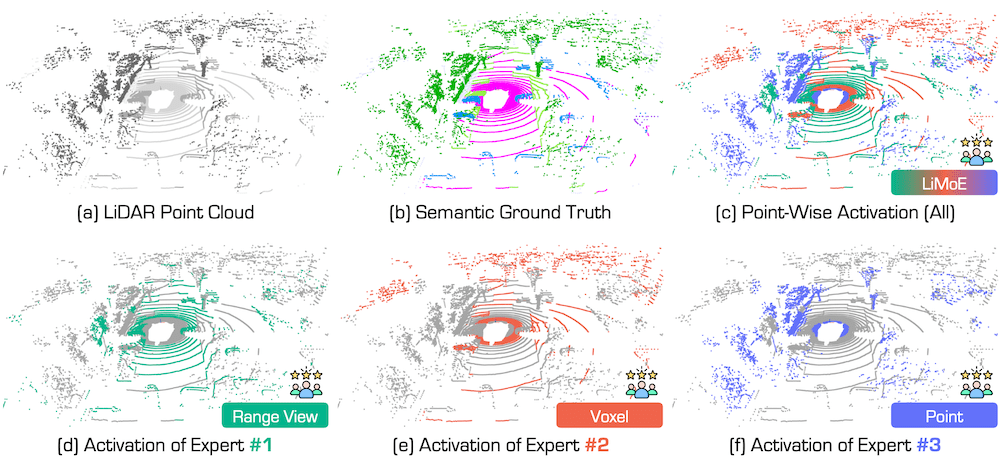
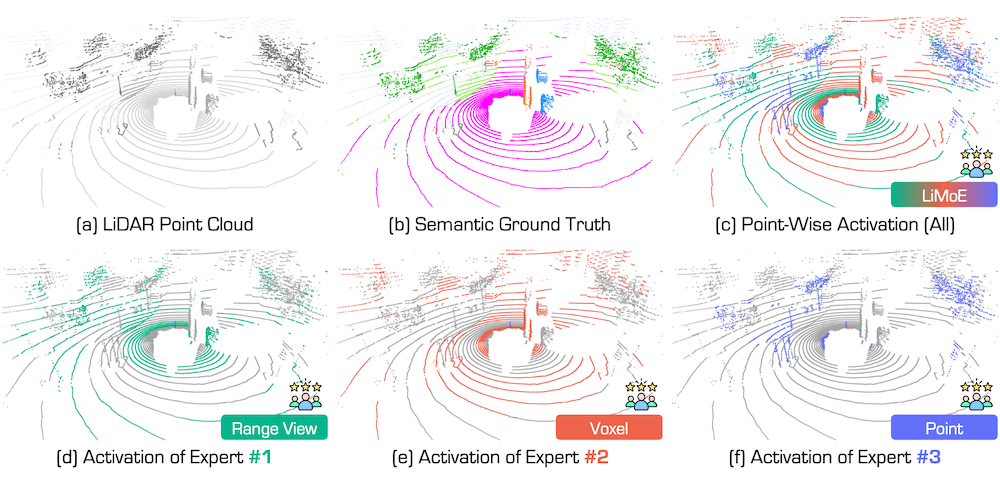 Figure 5. Point-wise top-1 activation path in the Semantic Mixture Supervision (SMS) stage.
It highlights the most activated representation for each point during the SMS stage, illustrating how different representations contribute to semantic segmentation based on spatial and object-specific characteristics.
Best viewed in colors.
Figure 5. Point-wise top-1 activation path in the Semantic Mixture Supervision (SMS) stage.
It highlights the most activated representation for each point during the SMS stage, illustrating how different representations contribute to semantic segmentation based on spatial and object-specific characteristics.
Best viewed in colors.
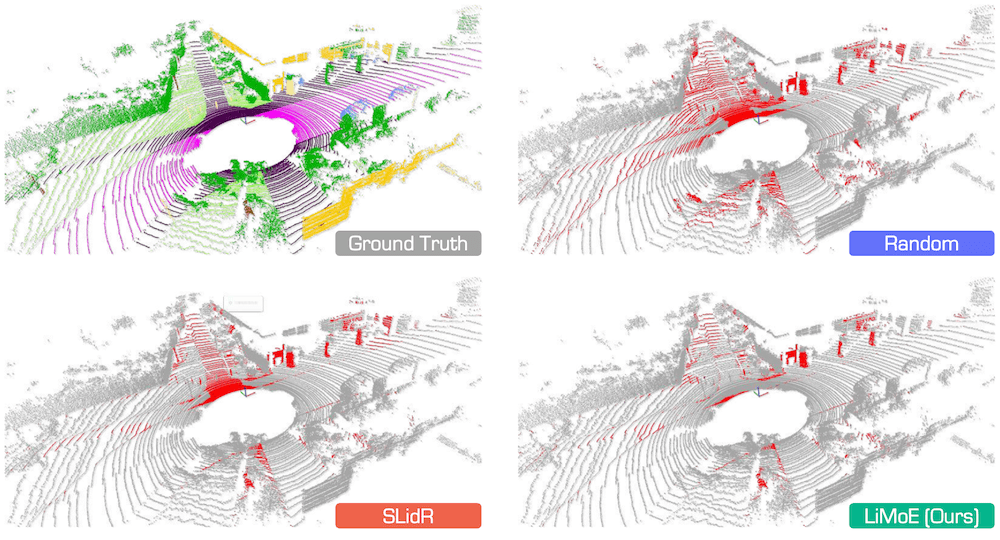
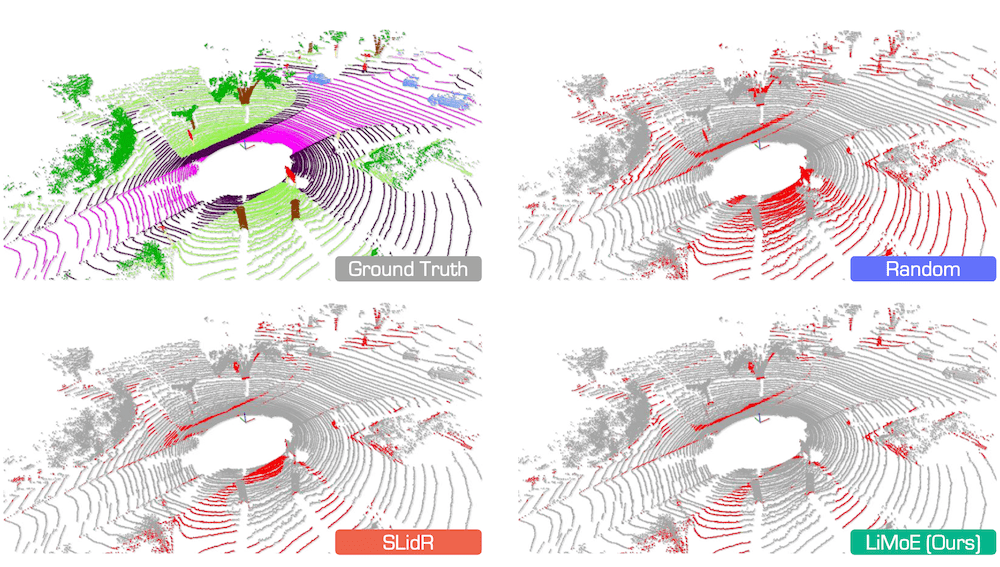 Figure 6. Qualitative assessments of state-of-the-art pretraining methods, pretrained on nuScenes and fine-tuned on SemanticKITTI with 1% annotations.
The error maps depict correct and incorrect predictions in gray and red, respectively.
Best viewed in colors.
Figure 6. Qualitative assessments of state-of-the-art pretraining methods, pretrained on nuScenes and fine-tuned on SemanticKITTI with 1% annotations.
The error maps depict correct and incorrect predictions in gray and red, respectively.
Best viewed in colors.
Bibtex
@article{xu2025limoe,
title={LiMoE: Mixture of LiDAR Representation Learners from Automotive Scenes},
author={Xu, Xiang and Kong, Lingdong and Shuai, Hui and Pan, Liang and Liu, Ziwei and Liu, Qingshan},
journal={arXiv preprint arXiv:2501.04004},
year={2025}
}