Unsupervised Video Domain Adaptation:
A Disentanglement Perspective
- 1ByteDance AI Lab
- 2National University of Singapore
- 3MBZUAI
- 4University of Technology Sydney
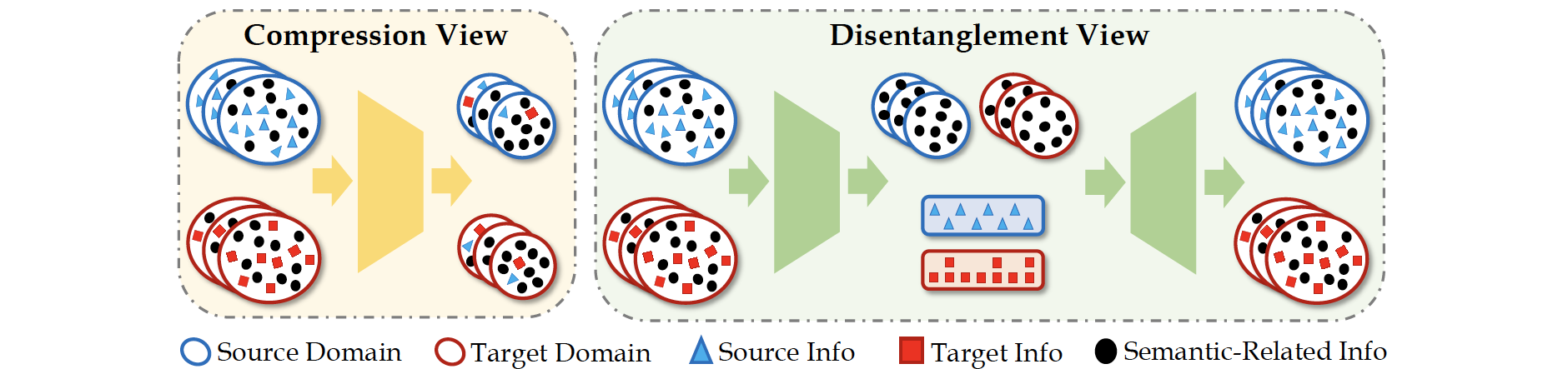
Figure 1. Conceptual comparisons between the traditional compression view and the proposed disentanglement view. Prior arts compress implicit domain information to obtain domain-indistinguishable representations; while in this work, we pursue explicit decouplings of domain-specific information from other information via generative modeling.
Abstract
Unsupervised video domain adaptation is a practical yet challenging task. In this work, for the first time, we tackle it from a disentanglement view.
Our key idea is to disentangle the domain-related information from the data during the adaptation process.
Specifically, we consider the generation of cross-domain videos from two sets of latent factors, one encoding the static domain-related information and another encoding the temporal and semantic-related information.
A Transfer Sequential VAE (TranSVAE) framework is then developed to model such generation. To better serve for adaptation, we further propose several objectives to constrain the latent factors in TranSVAE. Extensive experiments on the UCF-HMDB, Jester, and Epic-Kitchens datasets verify the effectiveness and superiority of TranSVAE compared with several state-of-the-art methods.
Resources




HighLights
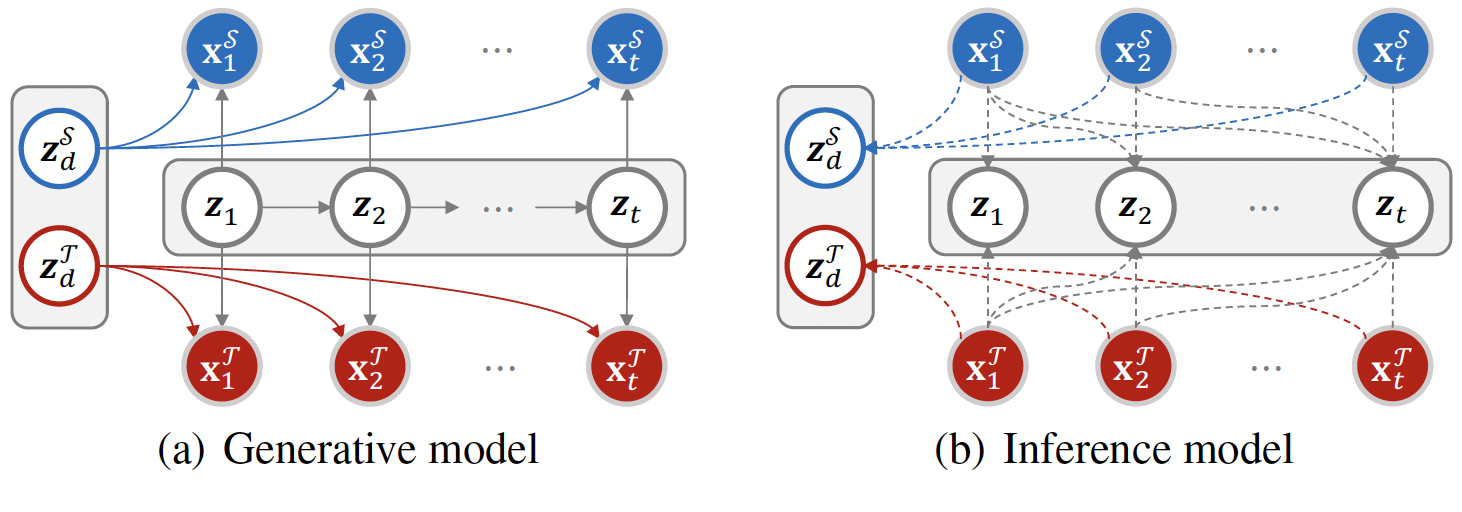 Figure 2. Graphical illustrations of the proposed generative
and inference models for sequential domain disentanglement.
Figure 2. Graphical illustrations of the proposed generative
and inference models for sequential domain disentanglement.
Sequential Domain Disentanglement
The blue/red nodes are the observed source/target videos xS/xT, respectively, over t timestamps. The static variables zdS and zdT follow a joint distribution and are domain-specific. Combining either of them with the dynamic variable zt at each timestamp, we can construct one frame data of a domain. Note that the sequences of the dynamic variables are shared across domains and are domaininvariant.
The blue/red nodes are the observed source/target videos xS/xT, respectively, over t timestamps. The static variables zdS and zdT follow a joint distribution and are domain-specific. Combining either of them with the dynamic variable zt at each timestamp, we can construct one frame data of a domain. Note that the sequences of the dynamic variables are shared across domains and are domaininvariant.
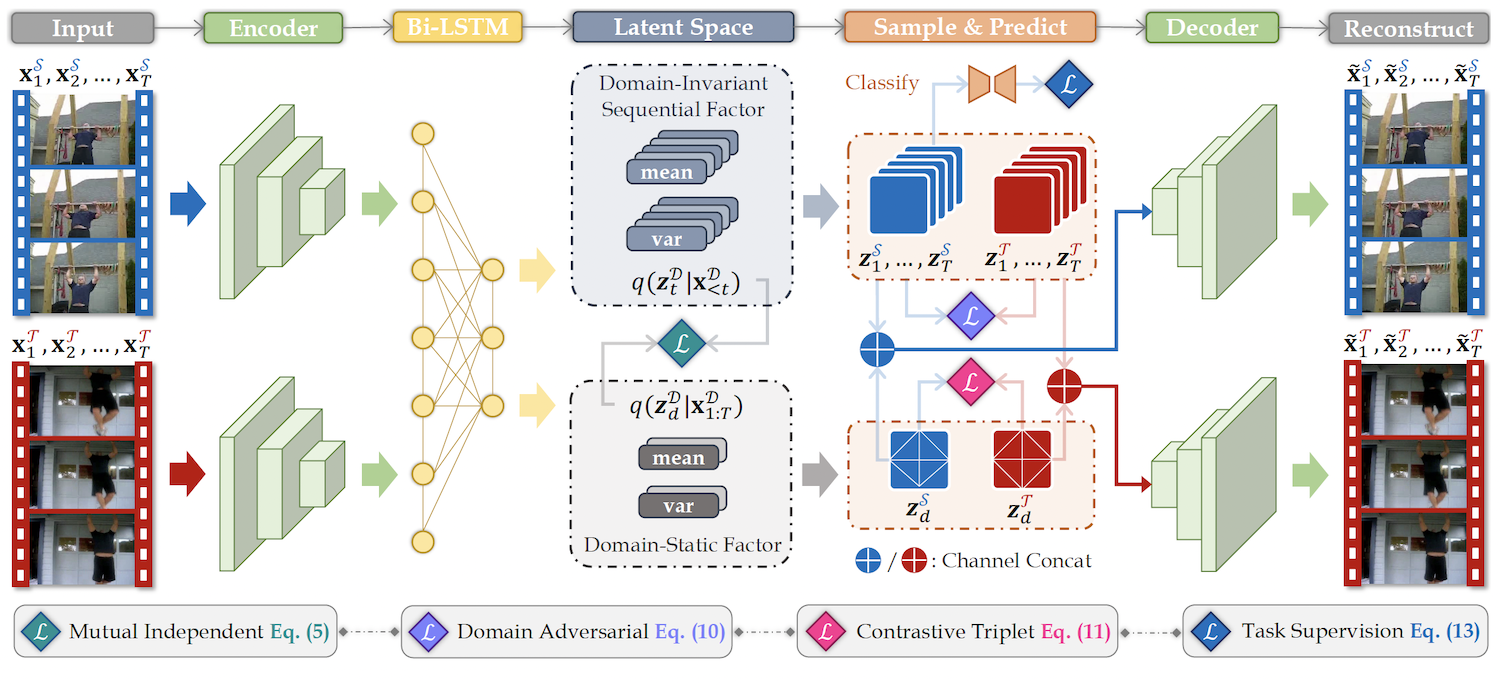 Figure 3. Overview of our TranSVAE framework.
The input videos are fed into an encoder to extract the visual features, followed by an LSTM to explore the temporal information.
Two groups of mean and variance networks are then applied to model the posterior of the latent factors, i.e.,
q(ztD|x<tD)
and q(zdD|x1:TD). The new representations z1D, ..., zTD
and zdD are sampled, and then concatenated and passed to an decoder for reconstruction. Four constraints are proposed to regulate the latent factors for adaptation purpose.
Figure 3. Overview of our TranSVAE framework.
The input videos are fed into an encoder to extract the visual features, followed by an LSTM to explore the temporal information.
Two groups of mean and variance networks are then applied to model the posterior of the latent factors, i.e.,
q(ztD|x<tD)
and q(zdD|x1:TD). The new representations z1D, ..., zTD
and zdD are sampled, and then concatenated and passed to an decoder for reconstruction. Four constraints are proposed to regulate the latent factors for adaptation purpose.
 Figure 4. Loss integration studies on UCF101 → HMDB51. Left: The t-SNE plots for class-wise (top row) and domain (bottom row, red
source & blue target) features. Right: Ablation results (%) by adding each loss sequentially, i.e., row (a) - row (e).
Figure 4. Loss integration studies on UCF101 → HMDB51. Left: The t-SNE plots for class-wise (top row) and domain (bottom row, red
source & blue target) features. Right: Ablation results (%) by adding each loss sequentially, i.e., row (a) - row (e).
 Figure 5. Loss integration studies on HMDB51 → UCF101. Left: The t-SNE plots for class-wise (top row) and domain (bottom row, red
source & blue target) features. Right: Ablation results (%) by adding each loss sequentially, i.e., row (a) - row (e).
Figure 5. Loss integration studies on HMDB51 → UCF101. Left: The t-SNE plots for class-wise (top row) and domain (bottom row, red
source & blue target) features. Right: Ablation results (%) by adding each loss sequentially, i.e., row (a) - row (e).
Bibtex
@article{wei2022transvae,
title={Unsupervised Video Domain Adaptation: A Disentanglement Perspective},
author={Wei, Pengfei and Kong, Lingdong and Qu, Xinghua and Yin, Xiang and Xu, Zhiqiang and Jiang, Jing and Ma, Zejun},
journal={arXiv preprint arXiv:2208.07365},
year={2022},
}