Lingdong Kong
![]()
![]()
![]()
![]()
![]()
I am a Ph.D. candidate in the Department of Computer Science at the National University of Singapore, advised by Prof. Wei Tsang Ooi, Prof. Benoit Cottereau, and Dr. Lai Xing Ng. I also collaborate closely with Prof. Ziwei Liu from Nanyang Technological University, Singapore.
I am an intern at Apple, working with Dr. Afshin Dehghan and Dr. Josh Susskind.
My research focuses include spatial intelligence, multimodal large language models, and 3D/4D world modeling and evaluations.
I am the recipient of the National Scholarship (Ministry of Education, 2019), Research Achievement Award (NUS Computing, 2023), Dean's Graduate Research Excellence Award (NUS Computing, 2024), DAAD AInet Fellowship (DAAD, 2025), and Apple Scholars in AI/ML Ph.D. Fellowship (Apple, 2025).
I have been fortunate to collaborate with Apple Machine Learning Research, NVIDIA Research, ByteDance AI Lab, OpenMMLab, MMLab@NTU, and Motional.
News
- [04/2026] - WorldLens was selected for oral presentation at CVPR 2026.
- [04/2026] - U4D was selected as a highlight at CVPR 2026.
- [11/2025] - LiDARCrafter was selected for oral presentation at AAAI 2026.
- [11/2025] - Selected for Global Young Scientists Summit (GYSS) 2026.
- [09/2025] - Talk2Event was selected as a spotlight at NeurIPS 2025.
- [06/2025] - We are hosting the RoboSense Challenge at IROS 2025.
- [05/2025] - Recognized as an Outstanding Reviewer by CVPR 2025.
-
[03/2025] - Selected as an Apple Ph.D. Scholar in AI/ML by
 Apple.
Apple.
- [02/2025] - DynamicCity was selected as a spotlight at ICLR 2025.
- [01/2025] - Calib3D was selected for oral presentation at WACV 2025.
- [09/2024] - Place3D was selected as a spotlight at NeurIPS 2024.
- [04/2024] - OpenESS was selected as a highlight at CVPR 2024.
- [11/2023] - We are hosting the RoboDrive Challenge at ICRA 2024.
- [09/2023] - Seal was selected as a spotlight at NeurIPS 2023.
- [03/2023] - LaserMix was selected as a highlight at CVPR 2023.
Research Highlights


Industrial Experience
Apple
Apple Scholar in AI/ML- Vision-language models, multimodal scene understanding.
- Mentor: Dr. Afshin Dehghan and Dr. Josh Susskind.
Xiaomi EV
Research Intern- Embodied foundation models for robotics and autonomous driving.
- Mentor: Dr. Long Chen
TikTok Global E-Commerce
Machine Learning Engineer Intern- Semantic retrieval from multi-lingual multi-condition query.
- Mentor: Tianshu Yang and Zhihui Zhang
NVIDIA Research
Research Intern- Vision-language-action models for autonomous systems.
- Mentor: Dr. Boris Ivanovic.
OpenMMLab
Research Intern- MMDetection3D: open-source 3D perception toolbox and benchmark.
- Mentor: Dr. Wenwei Zhang and Dr. Kai Chen.
ByteDance AI Lab
Research Scientist Intern- Action recognition, video understanding, domain adaptation.
- Mentor: Dr. Pengfei Wei.
Motional
Autonomous Vehicle Intern- LiDAR-based 3D semantic segmentation for autonomous vehicles.
- Mentor: Dr. Venice Erin Liong.
Recent Publications
* equal contributions ‡ project lead § corresponding author
|
|
Don't Overthink with Pixels: Efficient Reasoning for Segmentation |

|
Open-o3 Video: Grounded Video Reasoning with Spatio-Temporal Evidence |
|
|
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World |
|
|
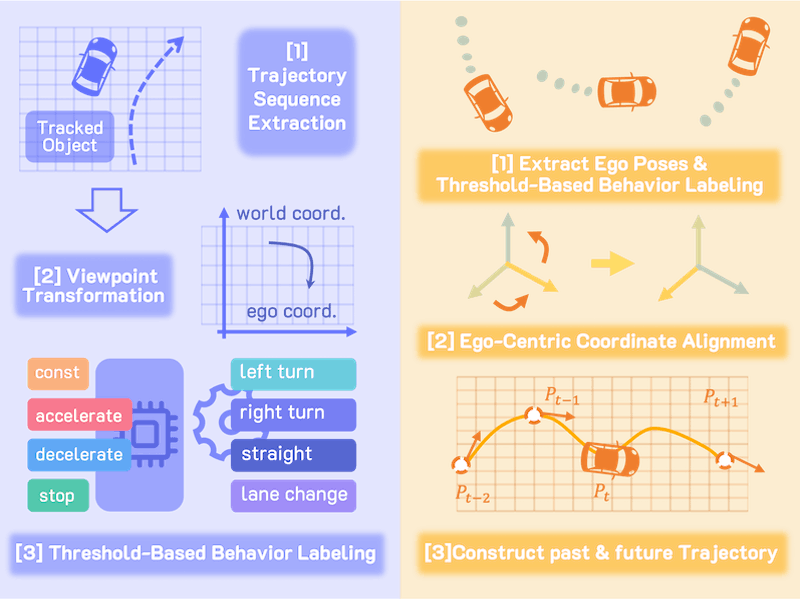
U4D: Uncertainty-Aware 4D World Modeling from LiDAR Sequences |

|
EditMGT: Unleashing Potentials of Masked Generative Transformers in Image Editing |

|
AadSFormer: Adaptive Serialized Transformers for Monocular Semantic Scene Completion from Indoor Environments |
|
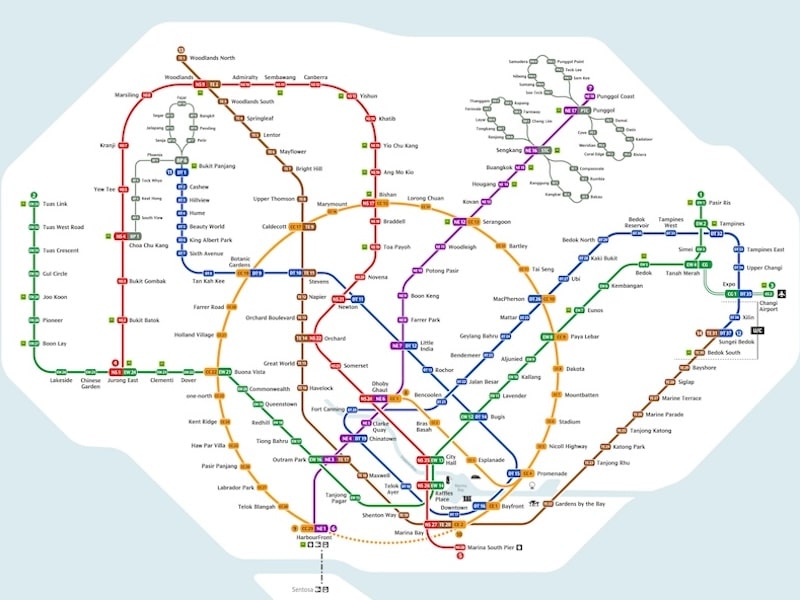
ReasonMap: Towards Fine-Grained Visual Reasoning from Transit Maps |
|
EventDrive: Event Cameras for Vision-Language Driving Intelligence |

|
AD-R1: Closed-Loop Reinforcement Learning for End-to-End Autonomous Driving with Impartial World Models |

|
AI for Auto-Research: Roadmap & User Guide
Preprint, 2026
|

|
3D and 4D World Modeling: A Survey
Preprint, 2026
|
|
|
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Preprint, 2026
|

|
OmniLiDAR: A Unified Diffusion Framework for Multi-Domain 3D LiDAR Generation
Preprint, 2026
|
|
|
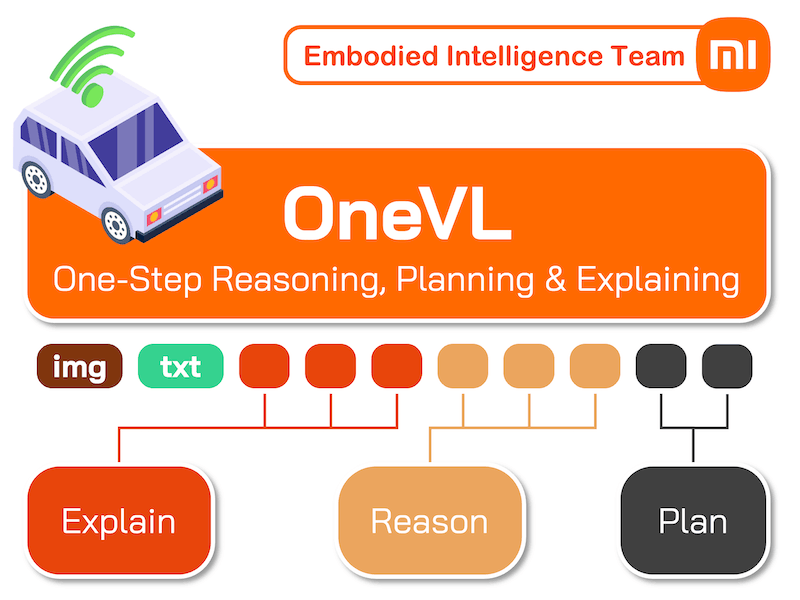
OneVL: One-Step Latent Reasoning with Vision-Language Explanation
Preprint, 2026
|
|
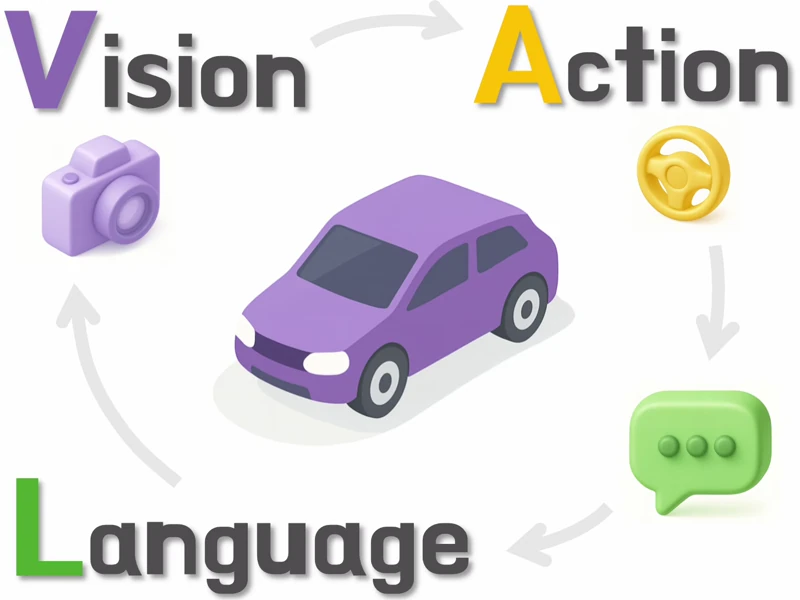
Vision-Language-Action Models for Autonomous Driving: Past, Present, Future
Preprint, 2026
|

|
HA-VLN 2.0: An Open Benchmark and Leaderboard for Human-Aware Navigation in Discrete and Continuous Environments
Preprint, 2026
|

|
FLUX: Accelerating Cross-Embodiment Generative Navigation Policies via Rectified Flow and Static-to-Dynamic Learning
Preprint, 2026
|

|
NavThinker: Action-Conditioned World Models for Coupled Prediction and Planning in Social Navigation
Preprint, 2026
|

|
Towards Unified World Models for Visual Navigation via Memory-Augmented Planning and Foresight
Preprint, 2026
|

|
Language-Conditioned World Modeling for Visual Navigation
Preprint, 2026
|

|
Semantic-Aware, Physics-Informed, Geometry-Grounded Weather Synthesis
Preprint, 2026
|

|
OneDay: Towards Full-Day Personalized Embodied Agents
Preprint, 2026
|

|
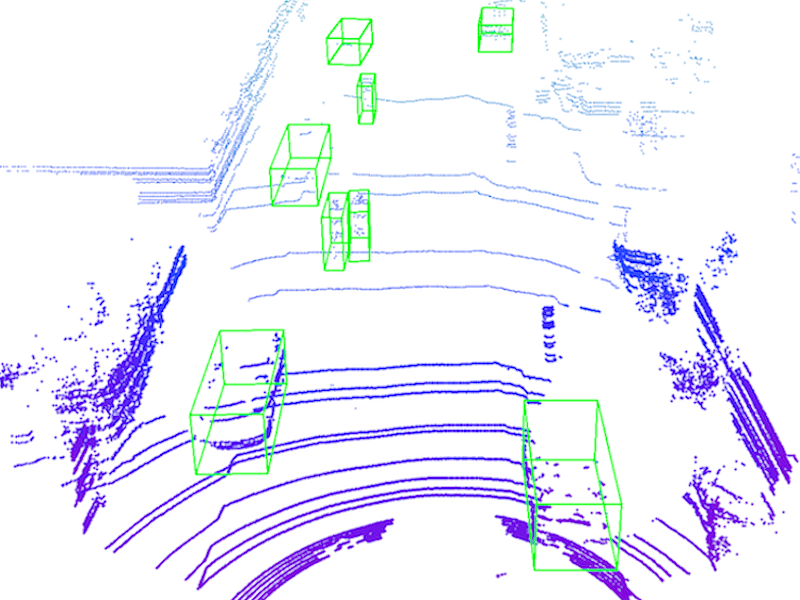
Learning to Remove Lens Flare in Event Camera
Preprint, 2026
|
|
Veila: Scaling Diffusion Models for Panoramic LiDAR Point Cloud Generation from a Single Image |
|
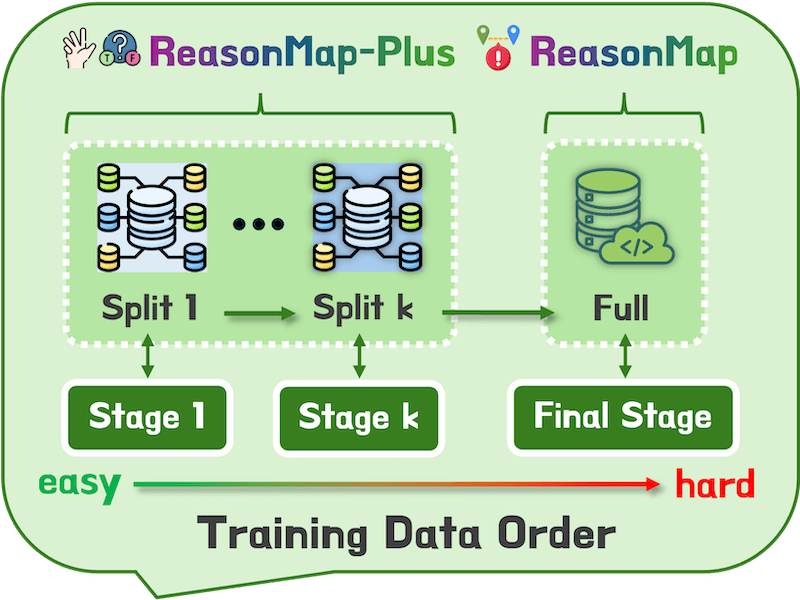
RewardMap: Tackling Sparse Rewards in Fine-Grained Visual Reasoning via Multi-Stage Reinforcement Learning |
|
|
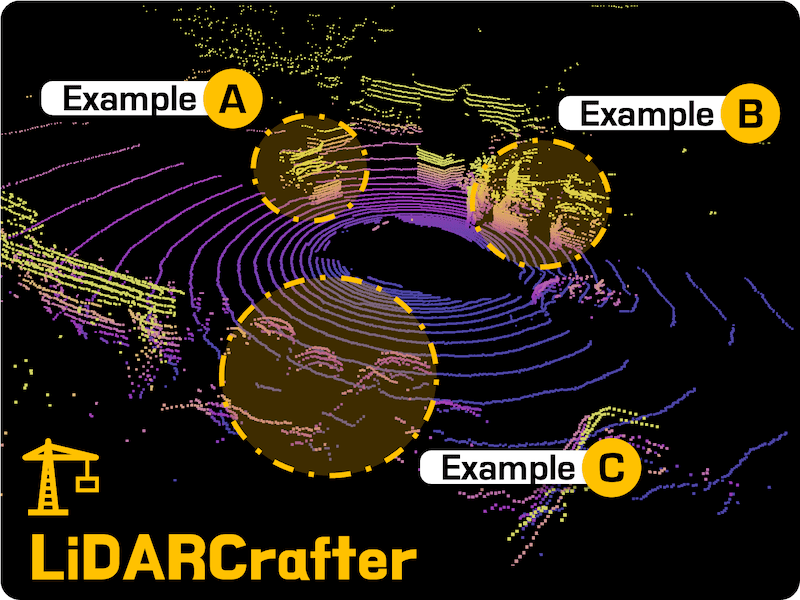
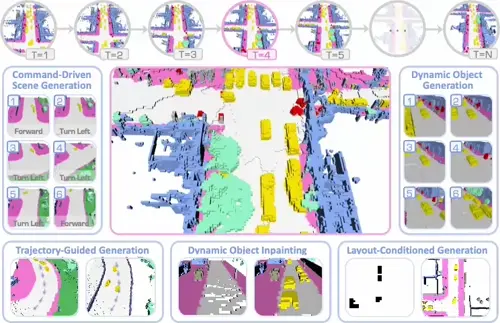
LiDARCrafter: Dynamic 4D World Modeling from LiDAR Sequences |
|
La La LiDAR: Large-Scale Layout Generation from LiDAR Data |

|
See4D: Pose-Free 4D Generation via Auto-Regressive Video Inpainting
EuroGraphics (EG), 2026
|
|
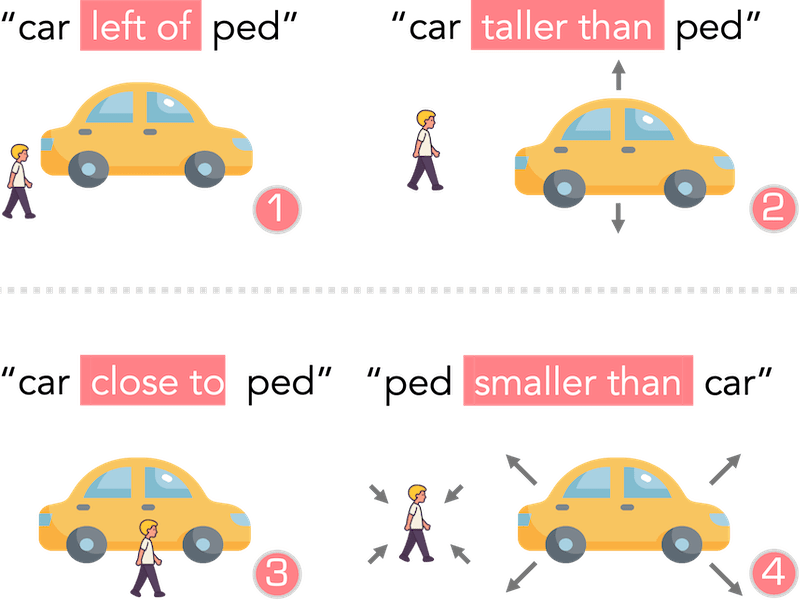
Enhanced Spatiotemporal Consistency for Image-to-LiDAR Data Pretraining |
|
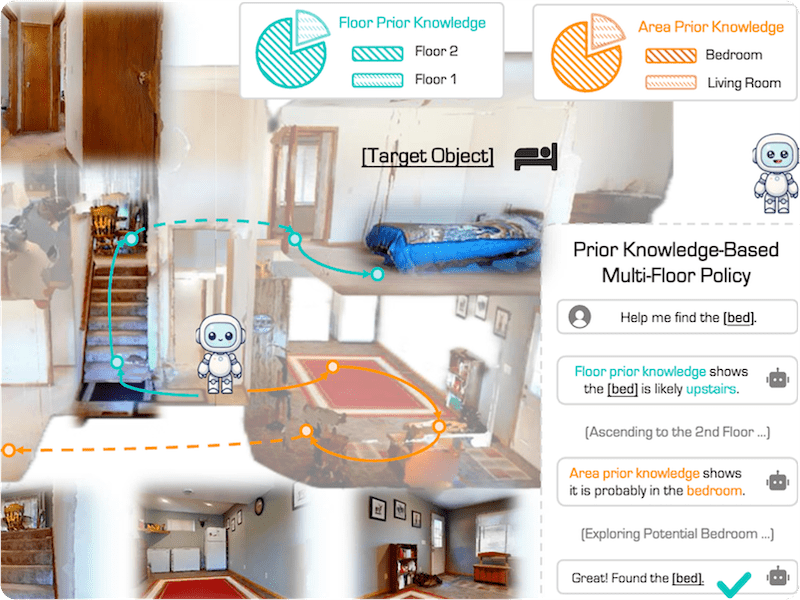
Stairway to Success: An Online Floor-Aware Zero-Shot Object-Goal Navigation Framework via LLM-Driven Coarse-to-Fine Exploration |
|
|
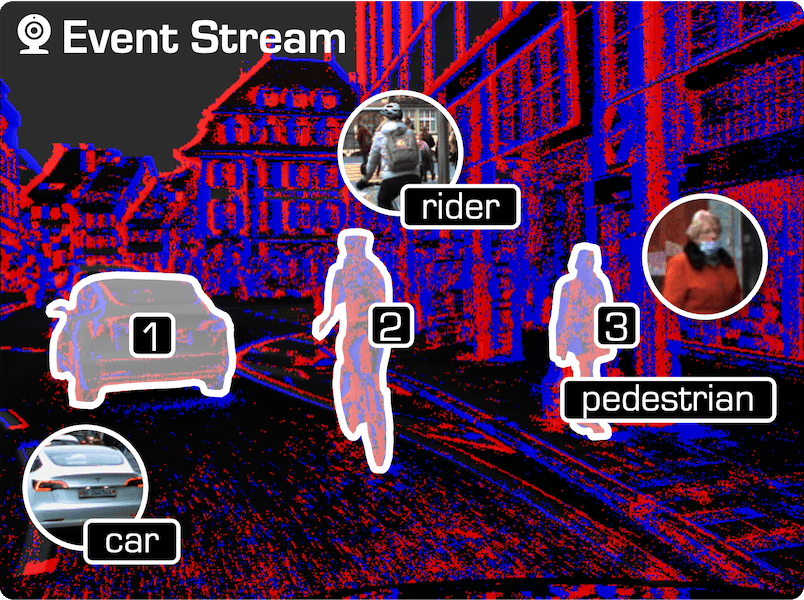
Talk2Event: Grounded Understanding of Dynamic Scenes from Event Cameras |
|
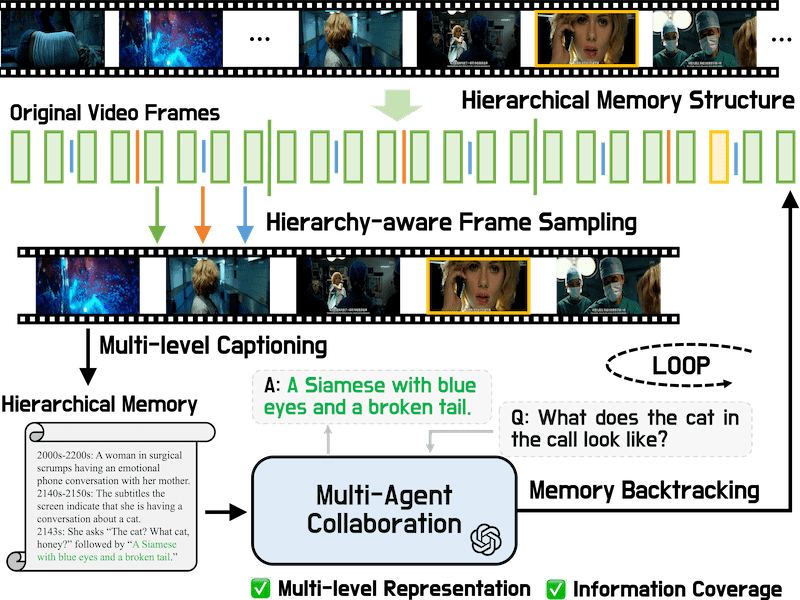
VideoLucy: Deep Memory Backtracking for Long Video Understanding |
|
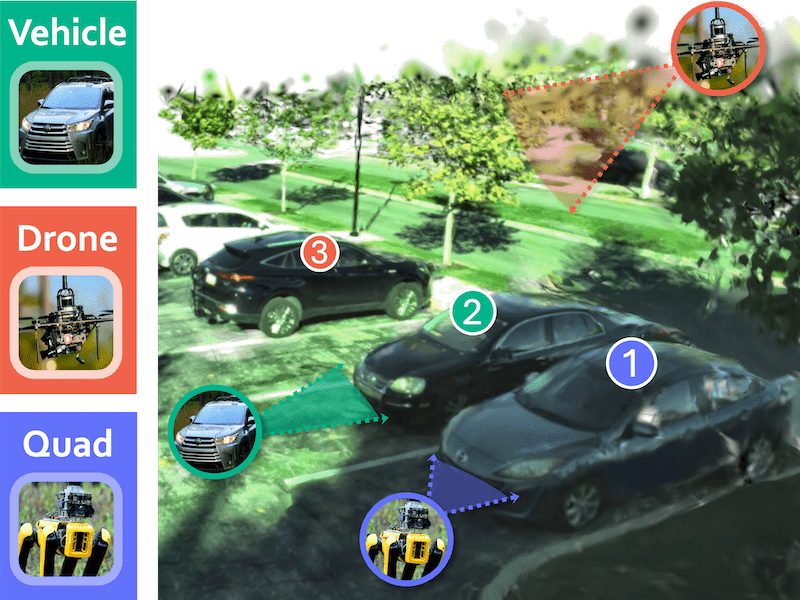
3EED: Ground Everything Everywhere in 3D |
|
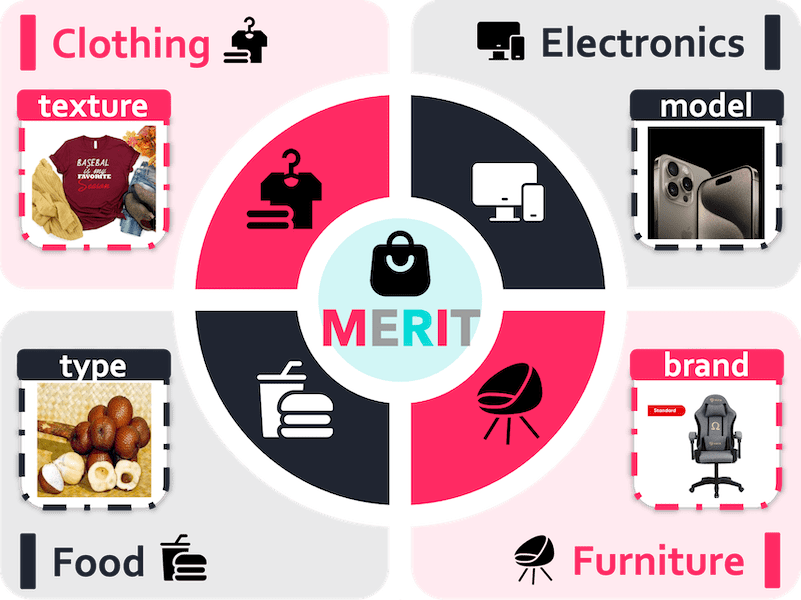
MERIT: Multilingual Semantic Retrieval with Interleaved Multi-Condition Query |

|
SPIRAL: Semantic-Aware Progressive LiDAR Scene Generation and Understanding |
|
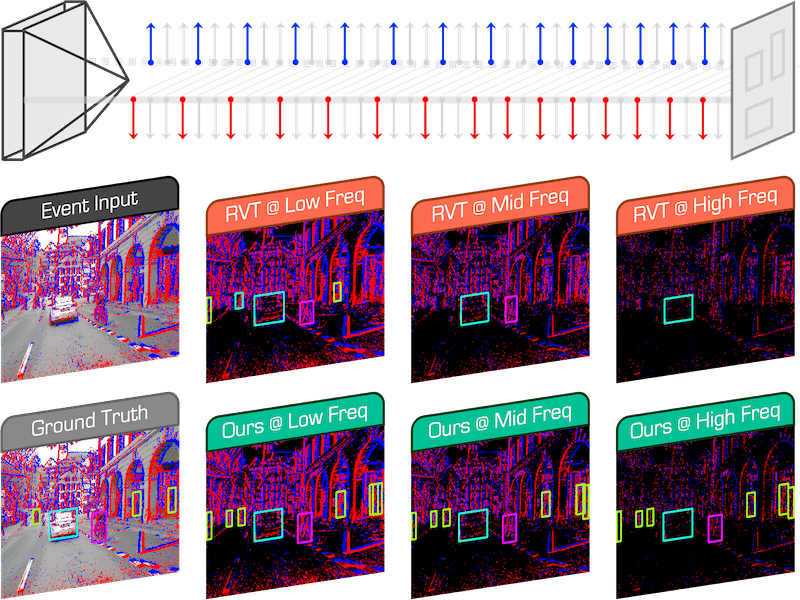
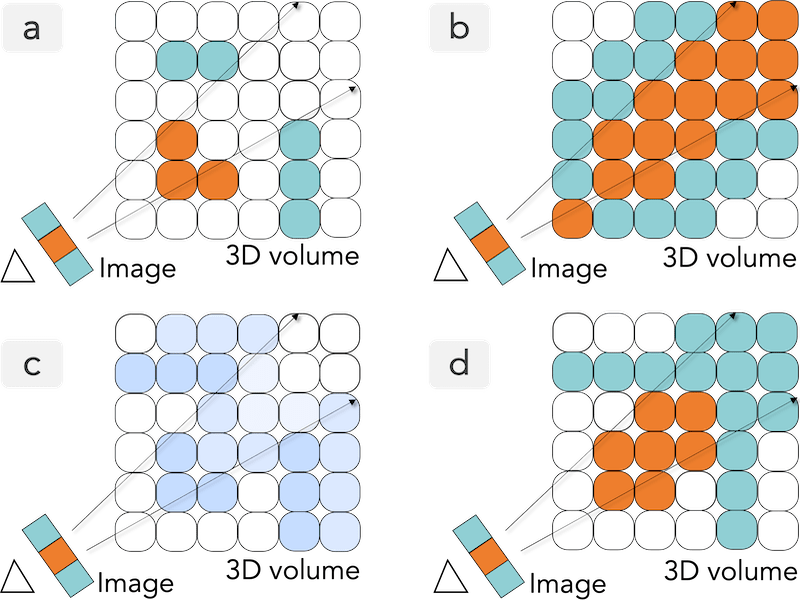
FlexEvent: Towards Flexible Event-Frame Object Detection at Varying Operational Frequencies |
|
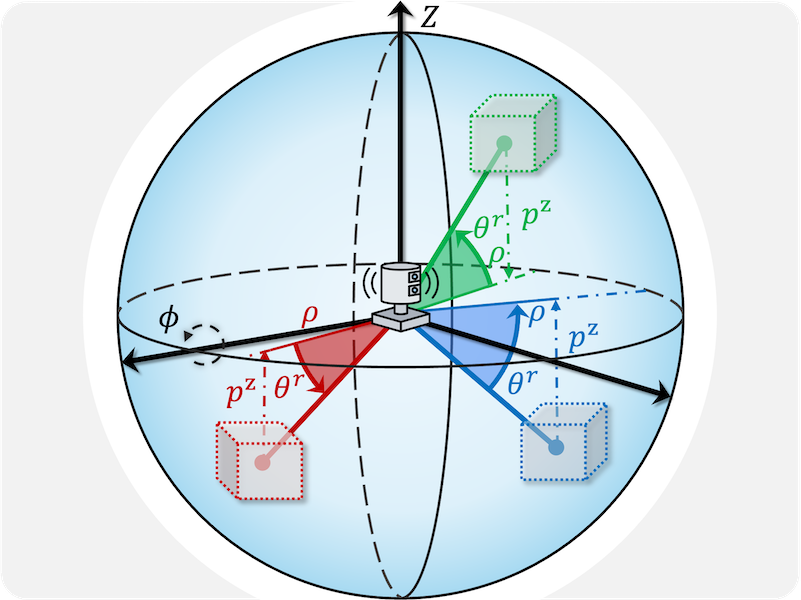
Perspective-Invariant 3D Object Detection |
|
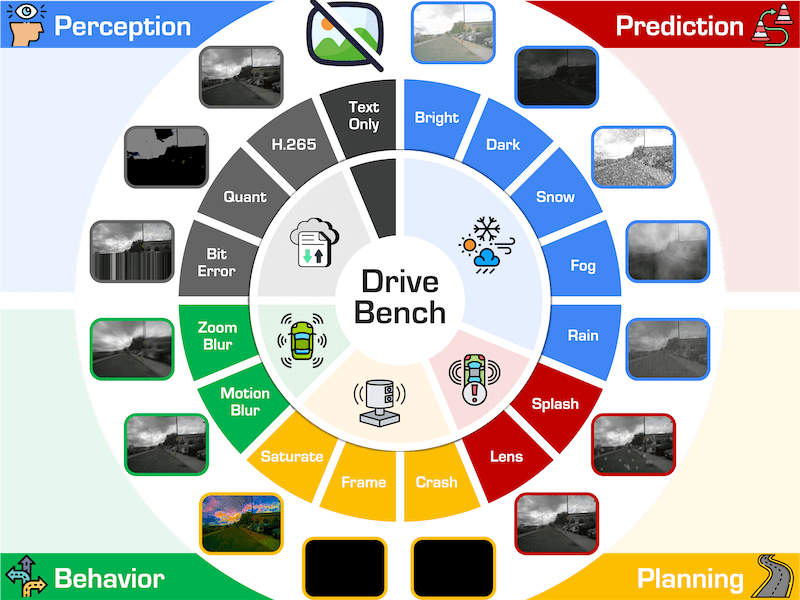
Are VLMs Ready for Autonomous Driving? An Empirical Study from the Reliability, Data, and Metric Perspectives |
|
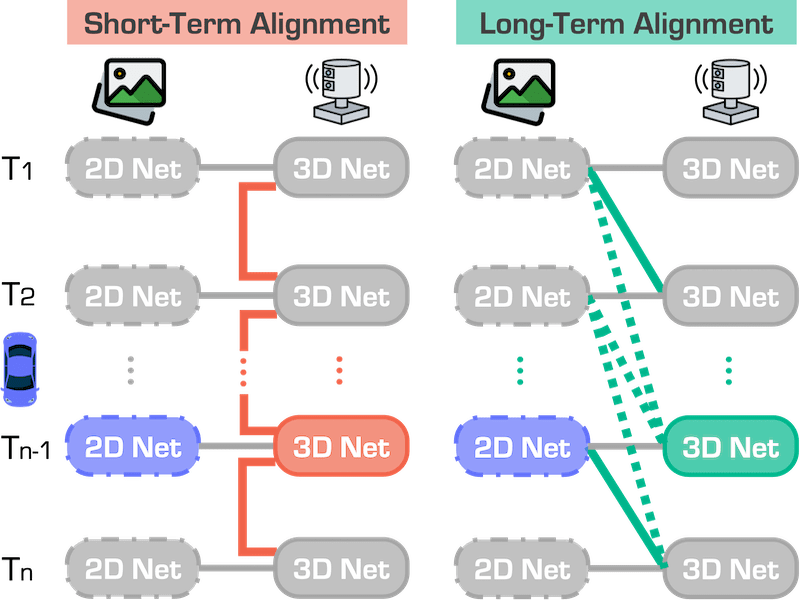
Beyond One Shot, Beyond One Perspective: Cross-View and Long-Horizon Distillation for Better LiDAR Representations |
|
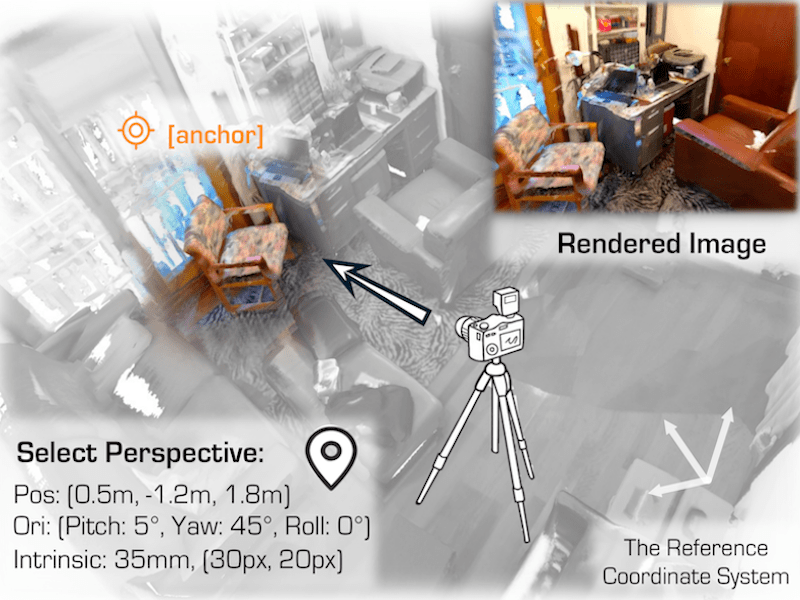
MonoMRN: Monocular Semantic Scene Completion via Masked Recurrent Networks |
|
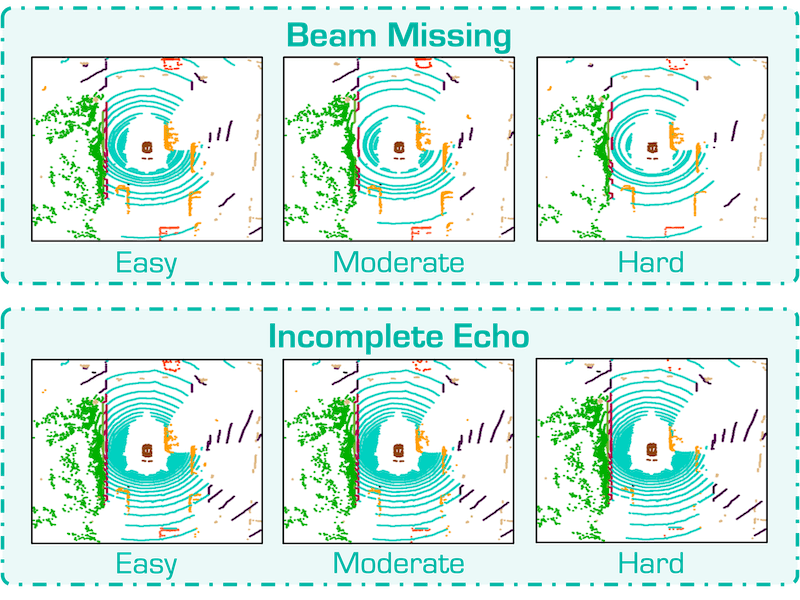
SafeMap: Robust HD Map Construction from Incomplete Observations |
|
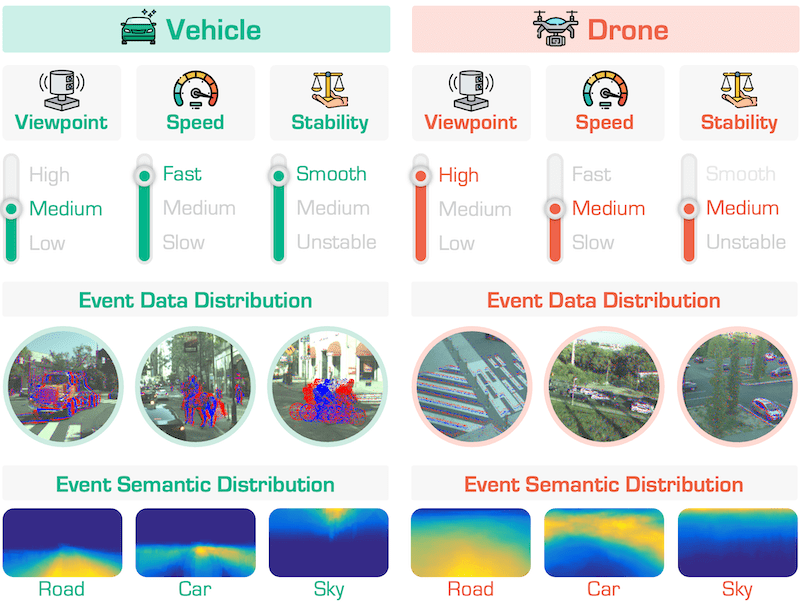
EventFly: Event Camera Perception from Ground to the Sky |
|
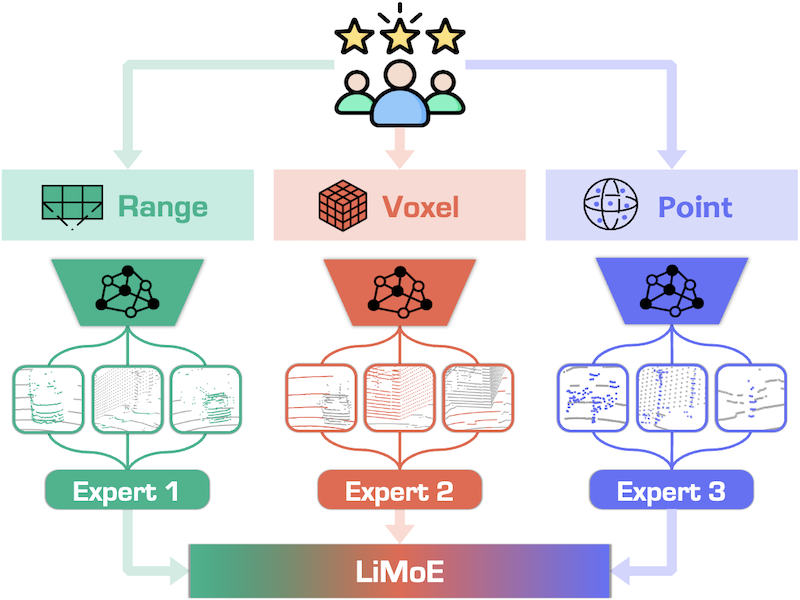
LiMoE: Mixture of LiDAR Data Representation Learners from Automotive Scenes |

|
GEAL: Generalizable 3D Object Affordance Learning with Cross-Modal Consistency |
|
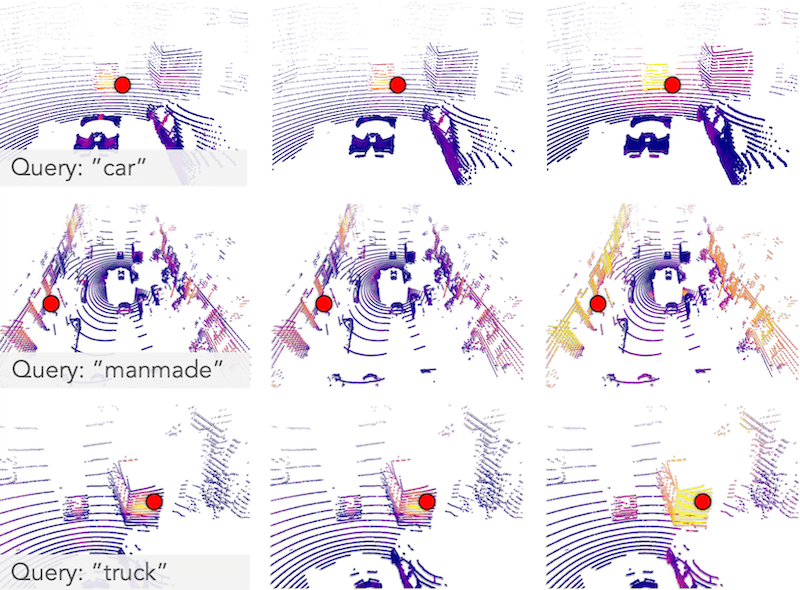
SeeGround: See and Ground for Zero-Shot Open-Vocabulary 3D Visual Grounding |
|
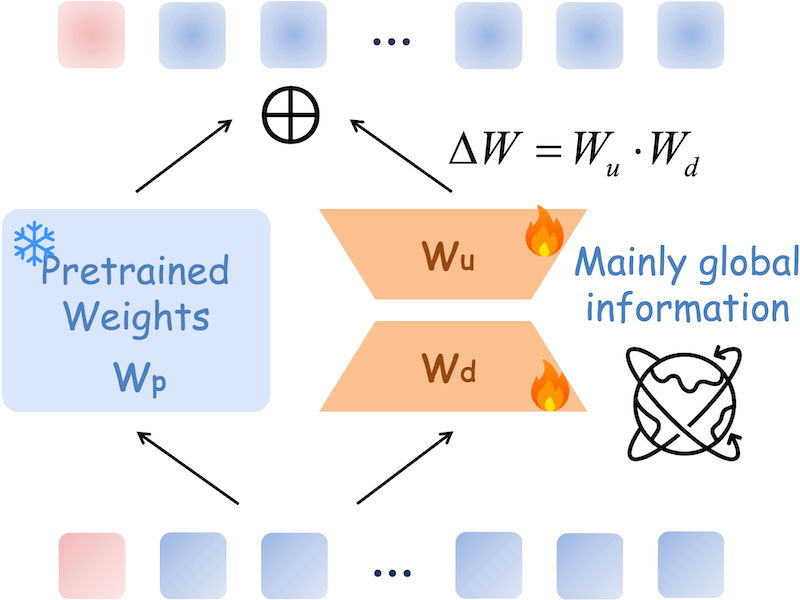
PointLoRA: Low-Rank Adaptation with Token Selection for Point Cloud Learning |
|
DynamicCity: Large-Scale 4D Occupancy Generation from Dynamic Scenes |
|
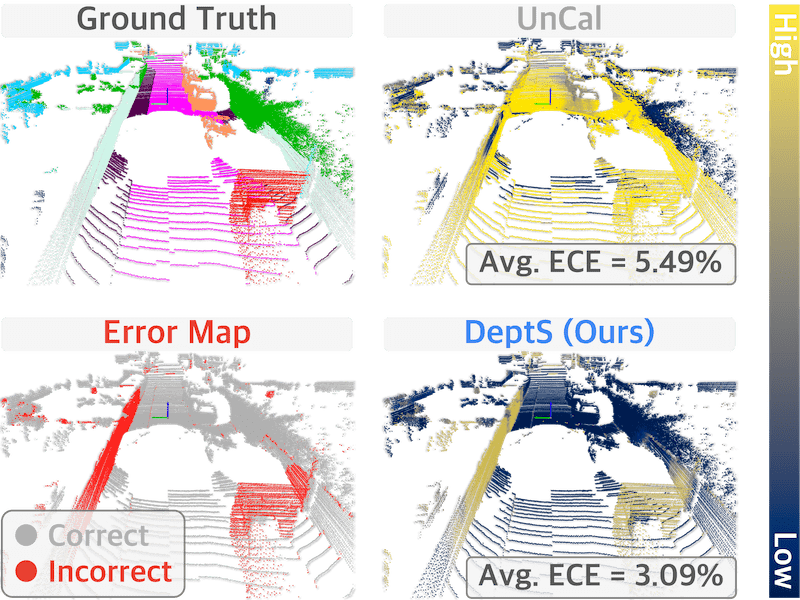
Calib3D: Calibrating Model Preferences for Reliable 3D Scene Understanding |
|
LargeAD: Large-Scale Cross-Sensor Data Pretraining for Autonomous Driving |
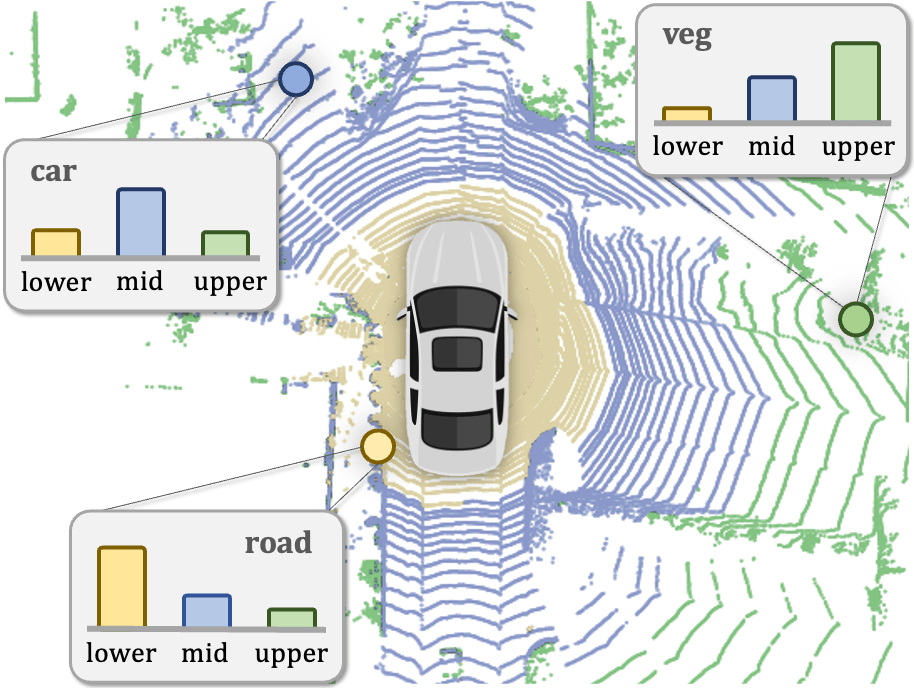
|
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving |
|
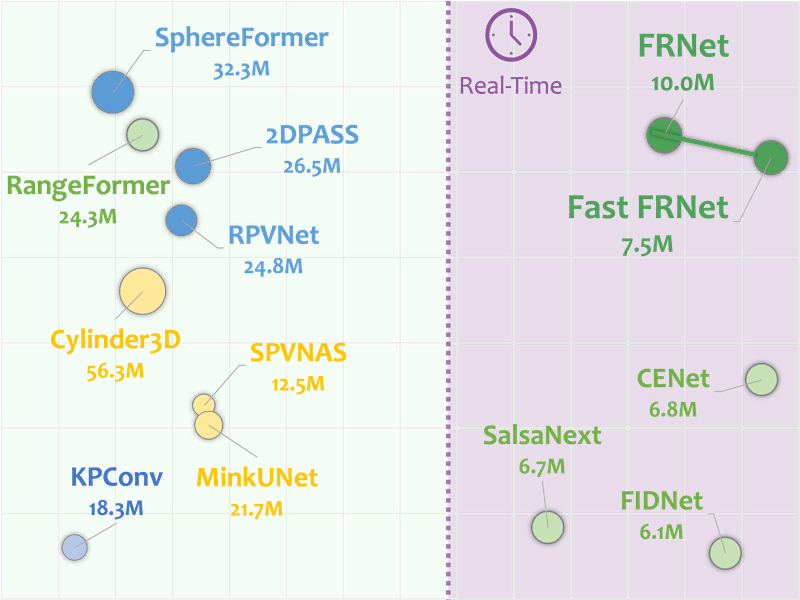
FRNet: Frustum-Range Networks for Scalable LiDAR-Based Semantic Segmentation |

|
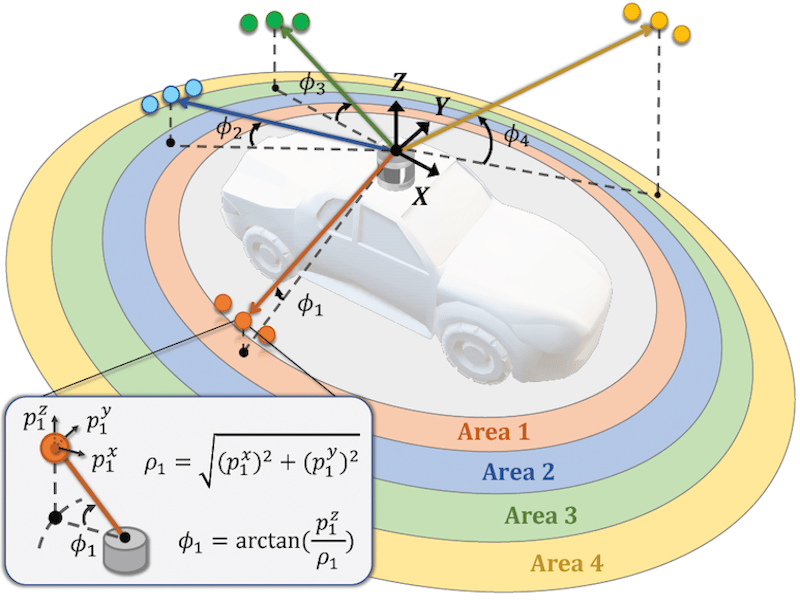
NUC-Net: Non-Uniform Cylindrical Partition Networks for Efficient LiDAR Semantic Segmentation |
|
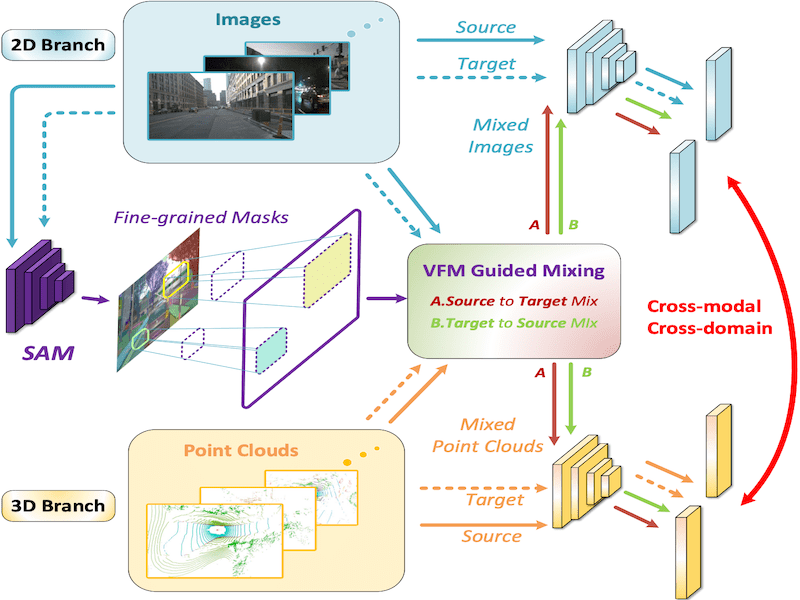
Visual Foundation Models Boost Cross-Modal Unsupervised Domain Adaptation for 3D Semantic Segmentation |
|
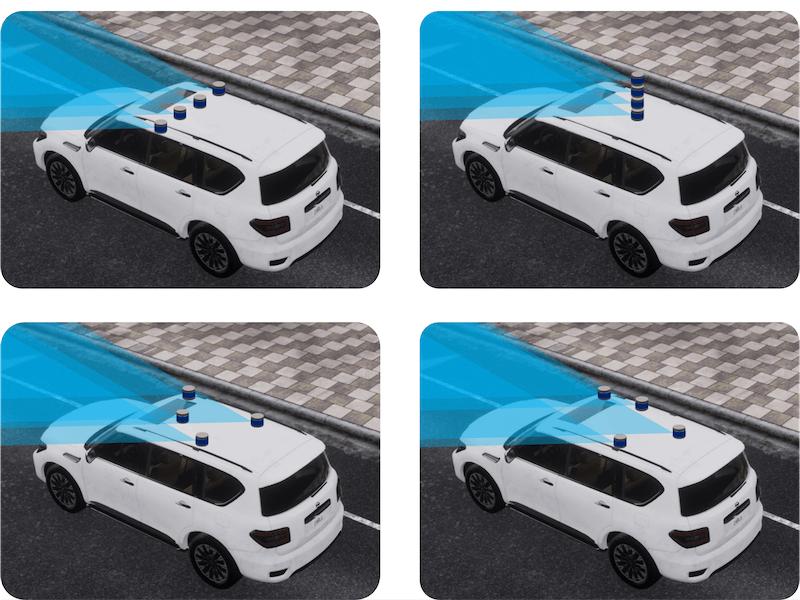
Is Your LiDAR Placement Optimized for 3D Scene Understanding? |
|
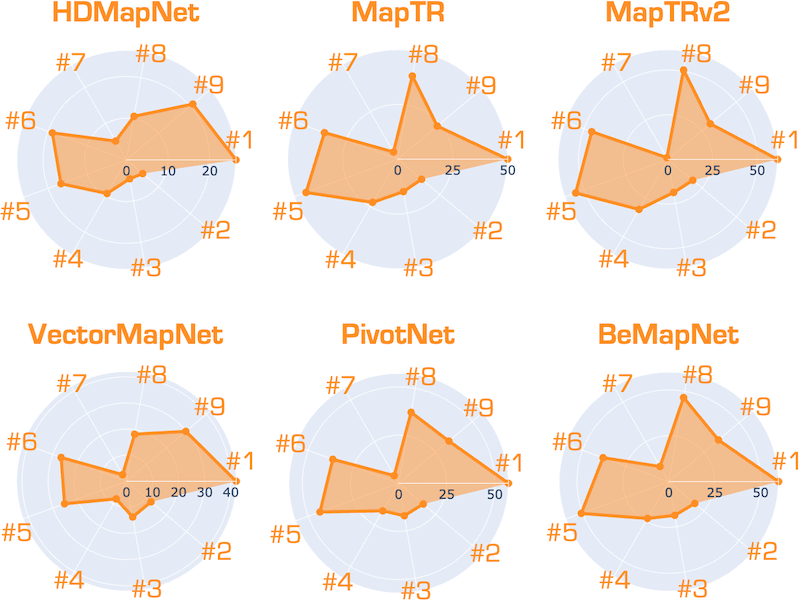
Is Your HD Map Constructor Reliable under Sensor Corruptions? |
|
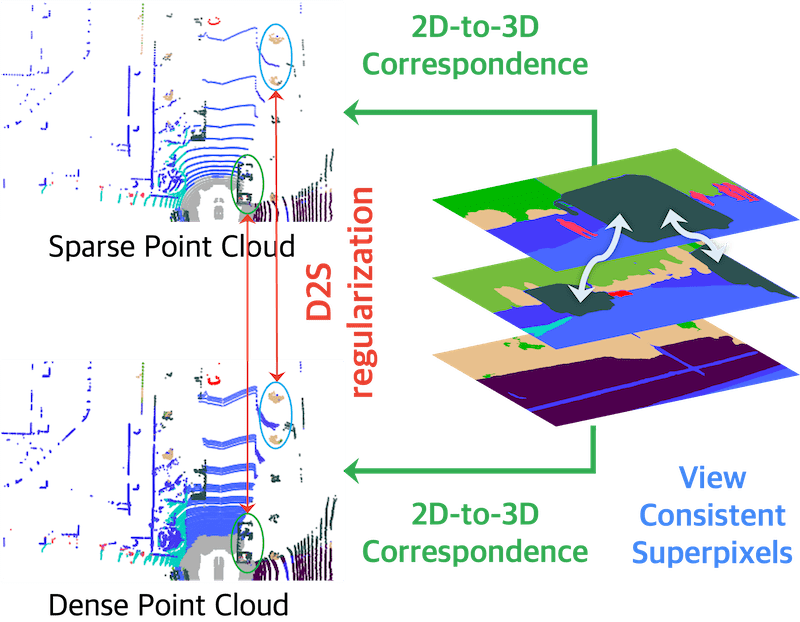
4D Contrastive Superflows are Dense 3D Representation Learners |

|
Learning to Adapt SAM for Segmenting Cross-Domain Point Clouds |

|
OpenESS: Event-Based Semantic Scene Understanding with Open Vocabularies |
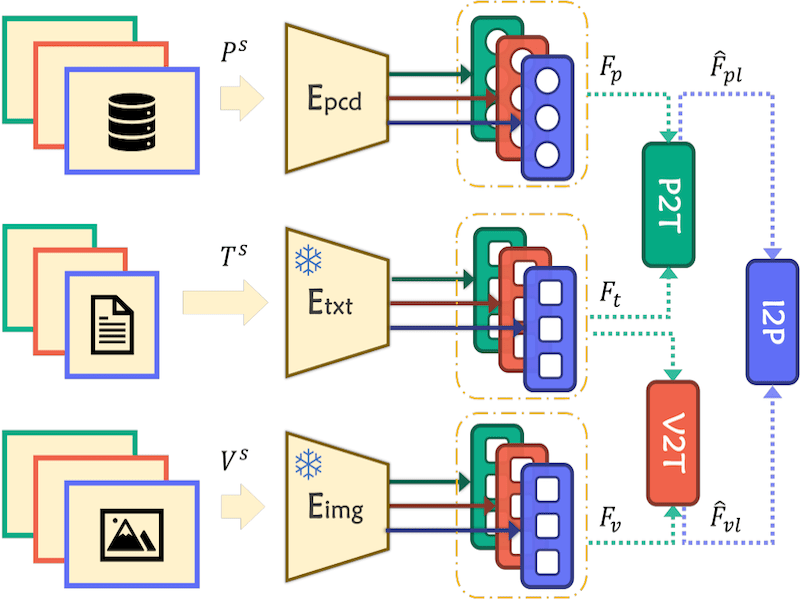
|
Multi-Space Alignments Towards Universal LiDAR Segmentation |
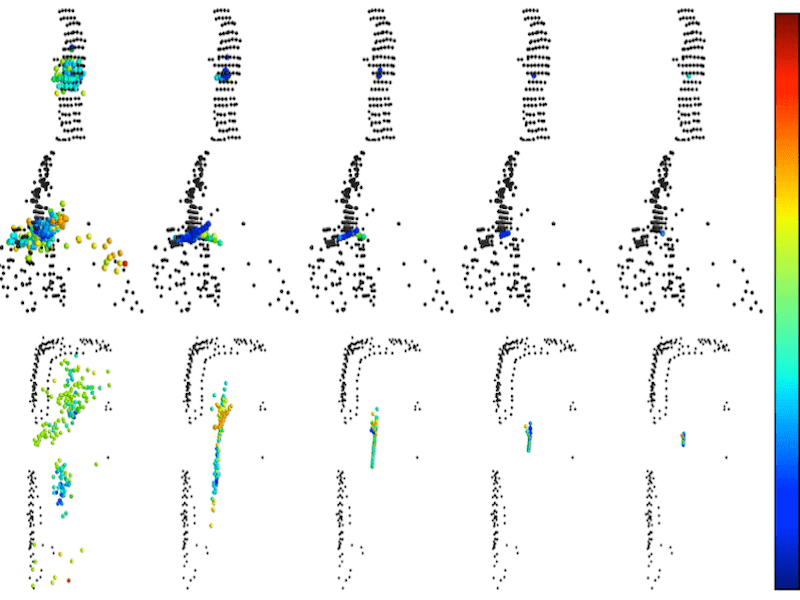
|
Unified 3D and 4D Panoptic Segmentation via Dynamic Shifting Networks |
|
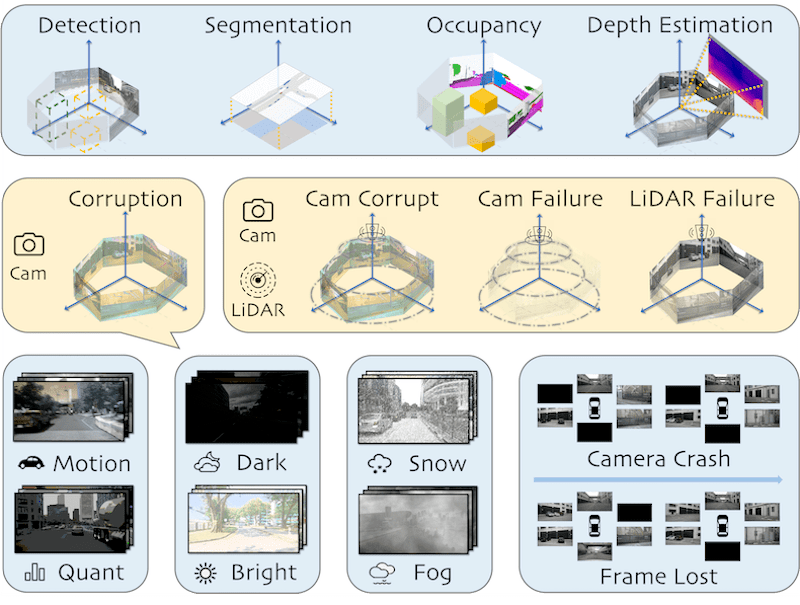
Benchmarking and Improving Bird's Eye View Perception Robustness in Autonomous Driving |
|
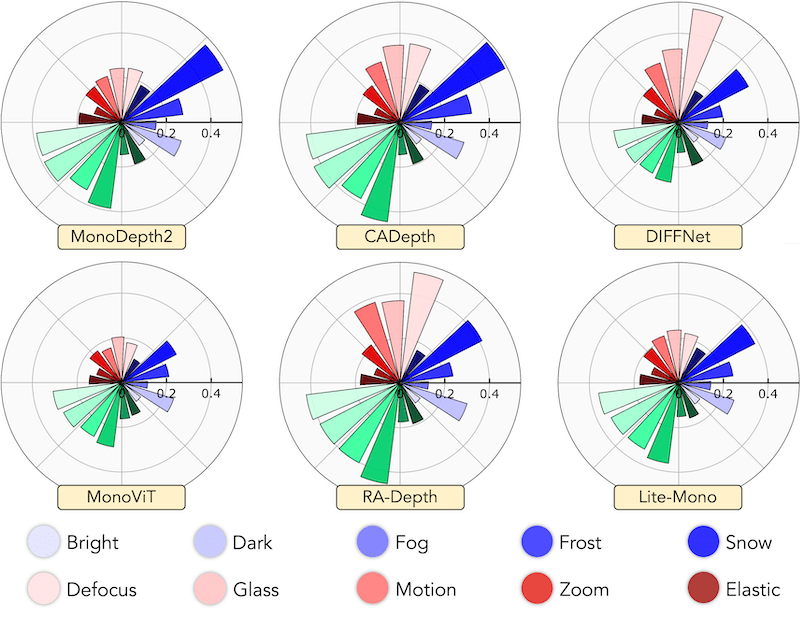
RoboDepth: Robust Out-of-Distribution Depth Estimation under Corruptions |
|
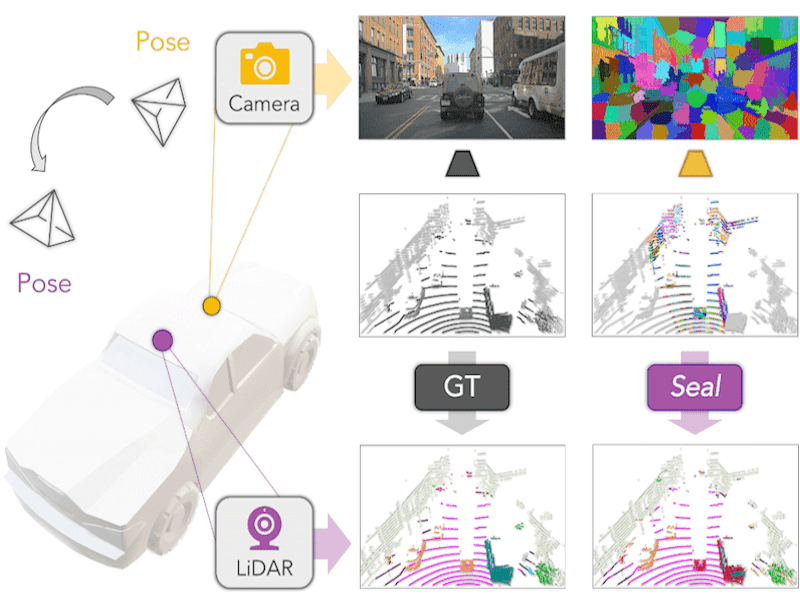
Segment Any Point Cloud Sequences by Distilling Vision Foundation Models |
|
|
Unsupervised Video Domain Adaptation for Action Recognition: A Disentanglement Perspective |
|
Towards Label-Free Scene Understanding by Vision Foundation Models |
|
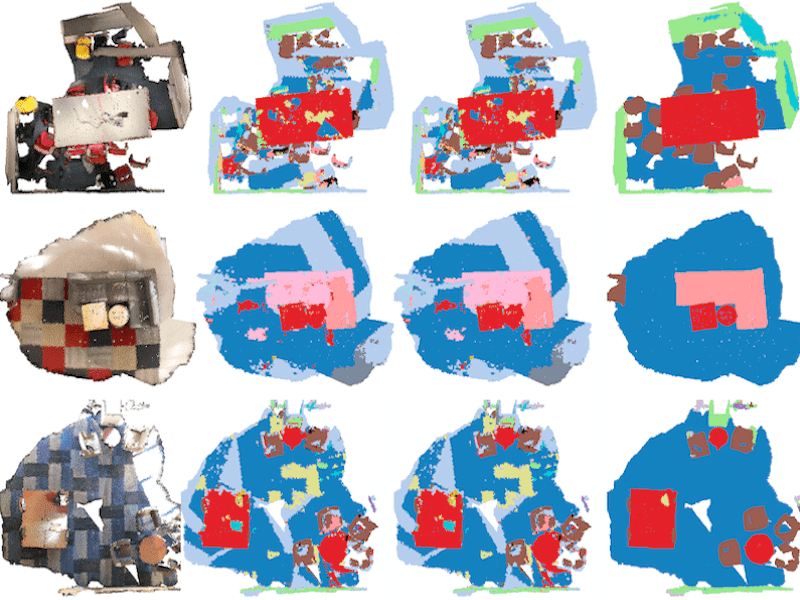
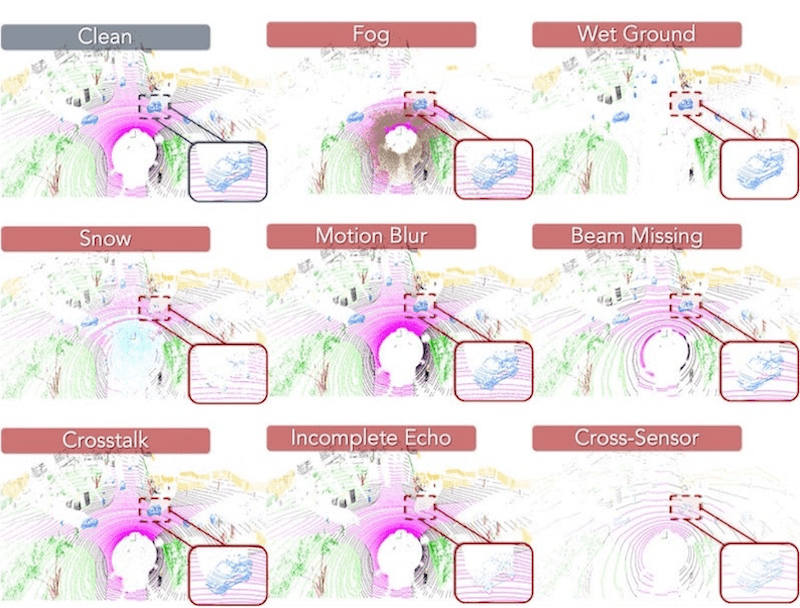
Robo3D: Towards Robust and Reliable 3D Perception against Corruptions |
|
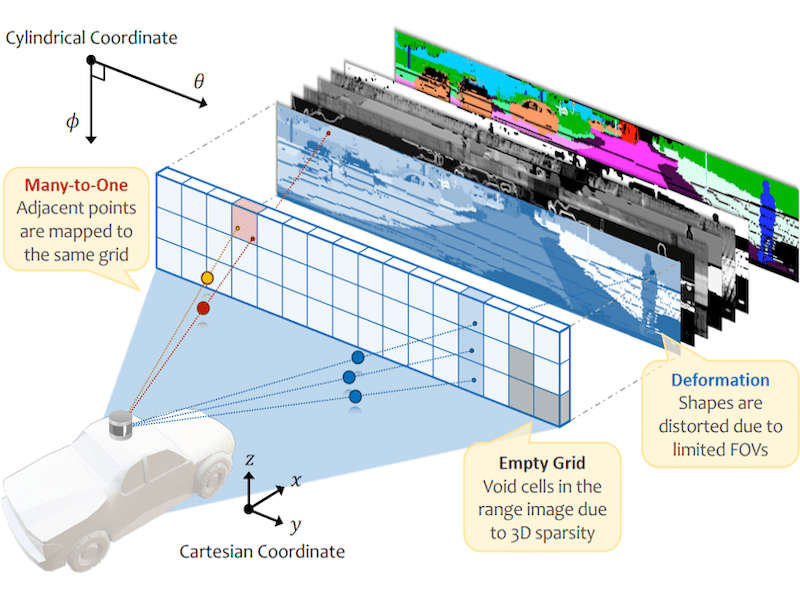
Rethinking Range View Representation for LiDAR Segmentation |
|
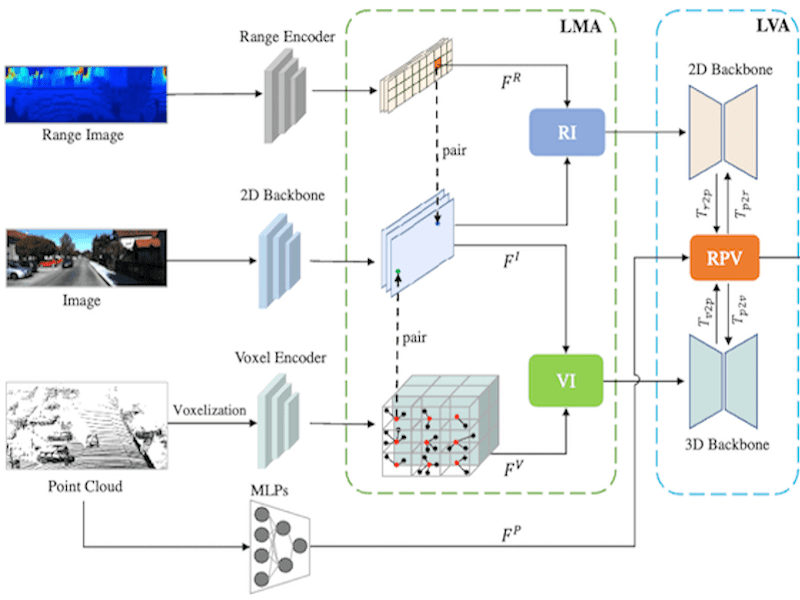
UniSeg: A Unified Multi-Modal LiDAR Segmentation Network and the OpenPCSeg Codebase |
|
LaserMix for Semi-Supervised LiDAR Semantic Segmentation |
|
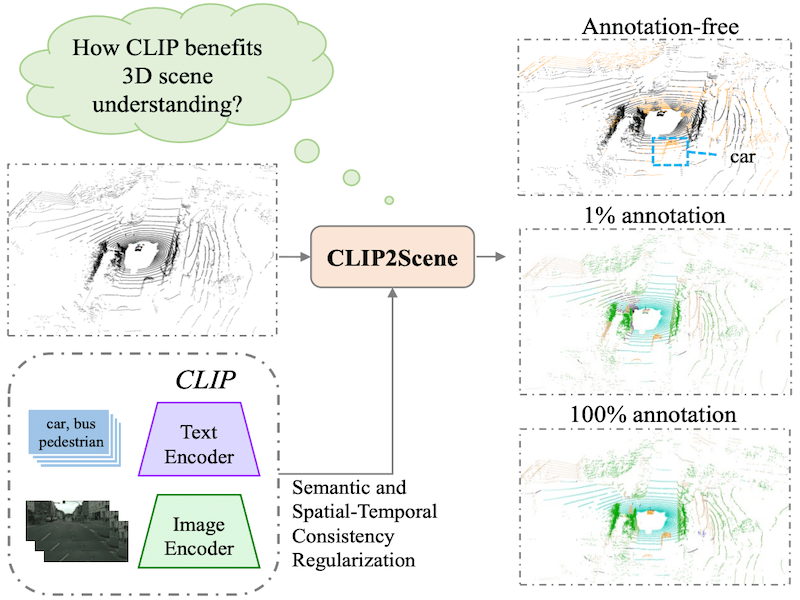
CLIP2Scene: Towards Label-Efficient 3D Scene Understanding by CLIP |

|
ConDA: Unsupervised Domain Adaptation for LiDAR Segmentation via Regularized Domain Concatenation |

|
Benchmarking 3D Robustness to Common Corruptions and Sensor Failure |
Tech Reports

|
The RoboWorld Challenge: Embodied World Modeling for Robotics and Autonomous Driving
Technical Report, 2026
|

|
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Technical Report, 2025
|

|
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
Technical Report, 2024
|

|
The RoboDepth Challenge: Methods and Advancements Towards Robust Depth Estimation
Technical Report, 2023
|
Workshop Organizers
Academic Services
Conference Reviewer
- IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
- IEEE/CVF International Conference on Computer Vision (ICCV)
- IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
- European Conference on Computer Vision (ECCV)
- Conference on Neural Information Processing Systems (NeurIPS)
- International Conference on Learning Representations (ICLR)
- International Conference on Machine Learning (ICML)
- IEEE International Conference on Robotics and Automation (ICRA)
- IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
- AAAI Conference on Artificial Intelligence (AAAI)
Journal Reviewer
- International Journal of Computer Vision (IJCV)
- International Journal of Robotics Research (IJRR)
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- IEEE Transactions on Neural Networks and Learning Systems (TNNLS)
- IEEE Transactions on Intelligent Vehicles (TIV)
- IEEE Transactions on Intelligent Transportation Systems (TITS)
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
- IEEE Transactions on Multimedia (TMM)
- IEEE Transactions on Knowledge and Data Engineering (TKDE)
- IEEE Robotics and Automation Letters (RA-L)
- ISPRS Journal of Photogrammetry and Remote Sensing (P&RS)